
深度学习在进行训练时,可能会用到多个数据,但是各个数据的重要程度是不同的,例如在 RNN 的介绍中,对 c1, c2, c3 的计算,实际上就是一种注意力机制,aij 表示重要程度

具体来说,注意力机制是通过如下的结构实现的:

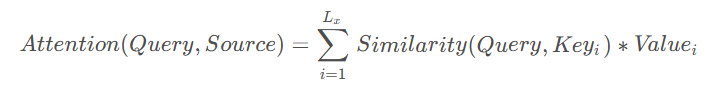
Query:需要计算的目标元素
key:source中元素的键值
value:source中元素的数值
similarity:相关性计算
计算可以分为以下3个阶段
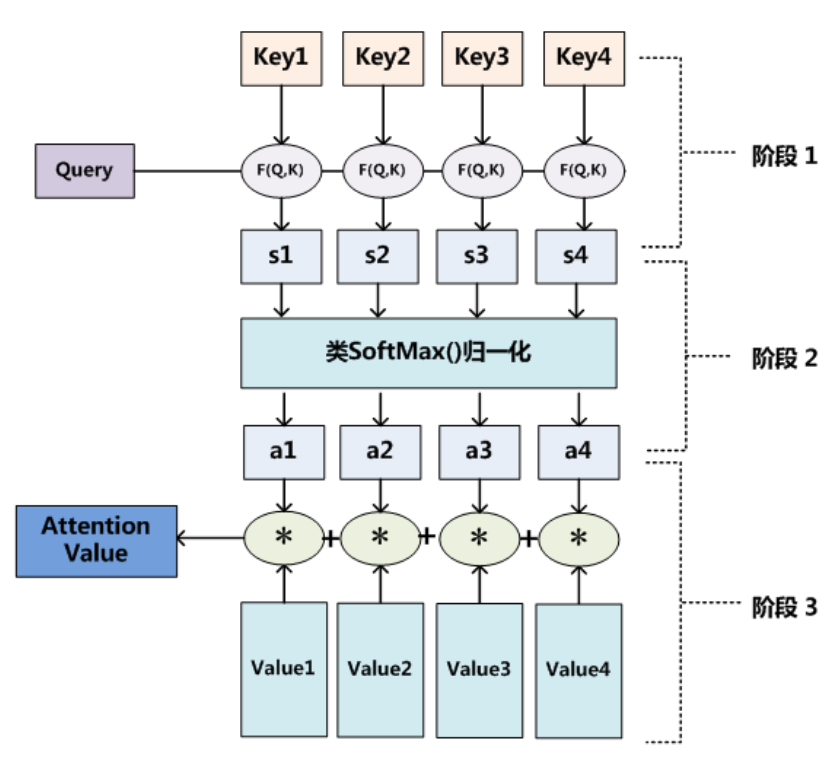
本质上 Attention 机制就是对 Source 中 key 元素的 Value 值进行加权求和,而对应 Value 的加权求和系数则表现了每个 value 重要程度,是通过 Query 和 Key 计算的(similarity,key 与 Query越相关,加权系数越大)
对于每个 RNN、LSTM 时间步,计算解码器当前输入状态和编码器输出的所有状态的相关性(transformer不是这样,其属于自注意力机制)
RNN 的例子中,每个 h (编码器的输出)的 Value,key 都是其本身,Query(解码器当前输入状态)分别是(h’0 ,h’1 ,h’2 假设预测 3 个时间步),最终Attention Value 分别是(c1,c2,c3),拿c3的计算举例:

如果是在时序分类任务中,只需要一个输出,下面是一个使用加性注意力实现该注意力机制的代码,如下所示
class Attention(nn.Module):
def __init__(self, hidden_size):
super(Attention, self).__init__()
self.hidden_size = hidden_size
self.attn = nn.Linear(hidden_size, hidden_size)
self.v = nn.Parameter(torch.rand(hidden_size)) # 定义一个可学习向量 v ,包装成 nn.Parameter,使其成为模型的参数
# 对注意力机制中的权重参数进行初始化,使用Xavier均匀分布初始化方法
# 自动根据张量的形状计算合适的范围,不需要手动指定
nn.init.xavier_uniform_(self.attn.weight)
# 对注意力机制中的偏置参数进行初始化,使用零初始化方法
nn.init.constant_(self.attn.bias, 0)
# 使用均匀分布初始化 query 参数,范围为 -0.1 到 0.1
nn.init.uniform_(self.v, -0.1, 0.1)
def forward(self, lstm_outputs):
"""
lstm_outputs: Tensor of shape (batch_size, seq_length, hidden_size)
"""
# 将h0,h1...... 的值映射到 (-1,1),实际上在加性注意力中
# energy = torch.tanh(self.attn(lstm_outputs) + self.attn(query)) ,lstm_outputs 是 keys
energy = torch.tanh(self.attn(lstm_outputs)) # (batch_size, seq_length, hidden_size)
# 将 v 向量处理格式,v: (hidden_size) -> (1, 1, hidden_size)
v = self.v.unsqueeze(0).unsqueeze(0) # (1, 1, hidden_size)
# 相关性计算,energy * v: (batch_size, seq_length, hidden_size)
energy = energy * v
# 求和计算得分: (batch_size, seq_length)
scores = energy.sum(dim=2)
# 计算注意力权重
# 对 scores 进行 Softmax 操作,确保权重在序列长度维度上归一化(即所有权重的和为 1)
attn_weights = torch.softmax(scores, dim=1) # (batch_size, seq_length)
# unsqueeze(1) 将 attn_weights 的形状从 (batch_size, seq_length) 转换为 (batch_size, 1, seq_length)
# 使用 torch.bmm(批量矩阵乘法)将注意力权重与 LSTM 输出(value)相乘
context = torch.bmm(attn_weights.unsqueeze(1), lstm_outputs) # (batch_size, 1, hidden_size)
context = context.squeeze(1) # (batch_size, hidden_size)
return context, attn_weights在常见的其他注意力机制应用中,Query、Key、Value 都是向量与 Q、K、V 三个矩阵相乘得到的,下面是自注意力机制的例子,Key 与 Query都是自己:
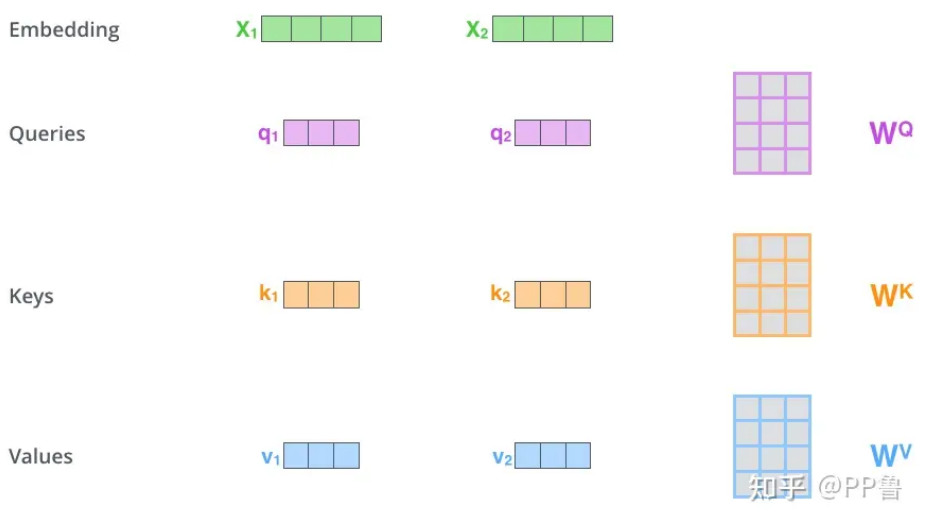

自注意力机制(Self-Attention)是深度学习中一种非常重要的机制,它允许序列中的每个元素在处理时与其他所有元素进行交互,并通过加权的方式聚合信息
对输入编码器的每个词向量,都创建 3 个向量,分别是:Query 向量,Key 向量,Value 向量。这 3 个向量是词向量分别和 3 个矩阵相乘得到的,而这个矩阵是我们要学习的参数
比如 q1 = x1 * Wq ,其他类似
注:这 3 个新得到的向量一般比原来的词向量的长度更小
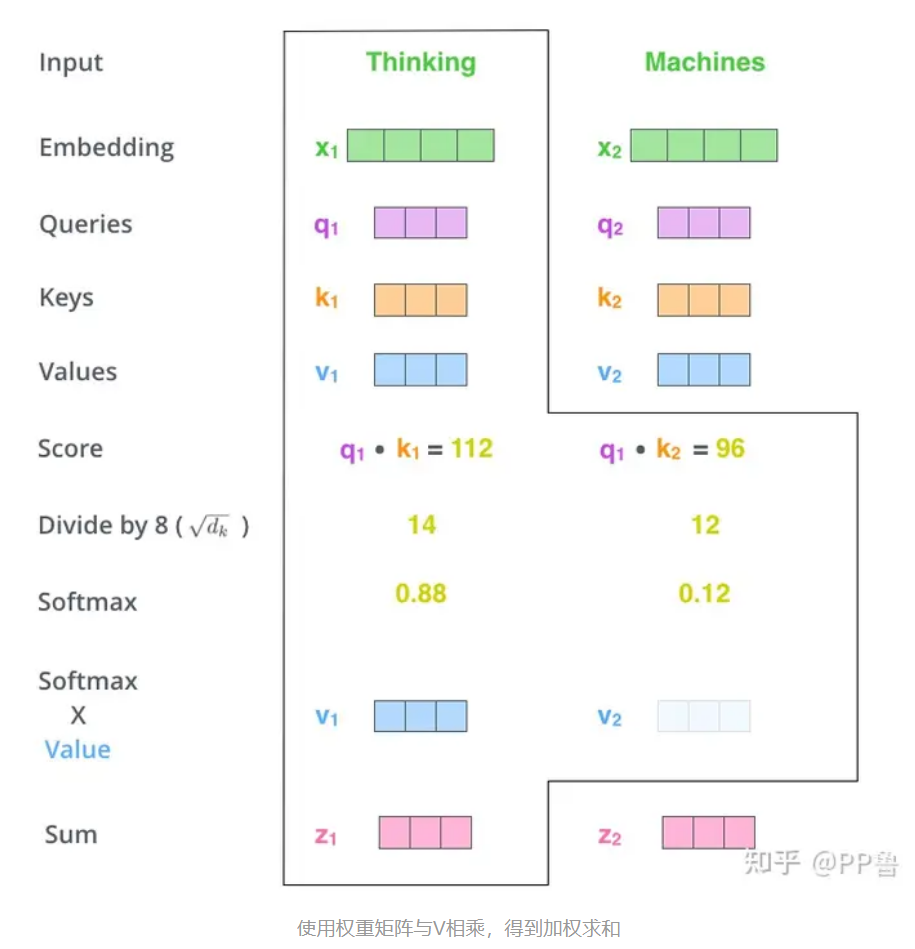
权重计算过程中,score 用的最简单的点积方式表示,算出每个 key 对应的score后再除以 (dk)^(1/2),dk 为k的维度大小,然后再通过 Softmax 计算出权重,也可以除以其他数,除以一个数是为了在反向传播时,求取梯度更加稳定
Transformer 用的即自注意力机制,具体在Transformer 部分中介绍
