1、DIN的注意力机制和transformer的注意力机制有啥区别
注意力范围:DIN是局部注意力,只计算了候选物品和历史行为的一个相关性,但是Transformer是全局计算了
计算方式不一样:DIN的话是将两个向量拼接或者相减,然后通过全连接层,Transformer是通过计算QKV矩阵,然后点乘后通过softmax激活函数得到权重
计算复杂度不一样:DIN是O(N),Transformer是O(N*2)
2、介绍下w2v中的skip-gram和CBOW
3、介绍下推荐系统的流程和对应的算法
召回、粗排、精排、重排
召回(从百万筛选到数百或者数千):协同过滤、双塔模型、基于内容的召回
粗排(百级候选,通过CTR预估,剔除点击率小于百分之一的商品):用一些轻量模型,比如LR
精排(对粗排结果进行精准排序)DIN、DIEN、SASRec
重排:对精排结果进行业务规则调优
协同过滤:

分为基于用户的协同过滤与基于物品的协同过滤
相似度计算:
余弦相似度(item-CF,即i2i),用户对a的评分向量和用户对b的评分向量做余弦相似度计算(未评分的用零填充),得到a,b的相似程度
皮尔逊相关系数(user-CF,即u2u2i),通过提取共同评估的物品,然后去中心化后,计算协方差与各个用户的标准差(协方差/各个用户标准差之积),得到皮尔逊相关系数
除了u2u2i和i2i外,还有u2i召回,直接为用户推荐item,比如双塔模型中的DSSM
基于内容的召回:
通过计算物品特征向量与用户兴趣向量的相似性来推荐物品
可以更好的解决冷启动问题,item-CF是通过用用户评分向量来计算物品相似度,新物品没有评分的,所以新物品难以推荐,但是基于内容的召回,无论是新物品还是新用户,都有各自的特征,可以直接参与召回,解决冷启动问题
双塔模型DSSM:
一个user塔(Query塔)和一个item塔(Document塔),各自的目的是得到user和item的embedding,然后进行相似度计算
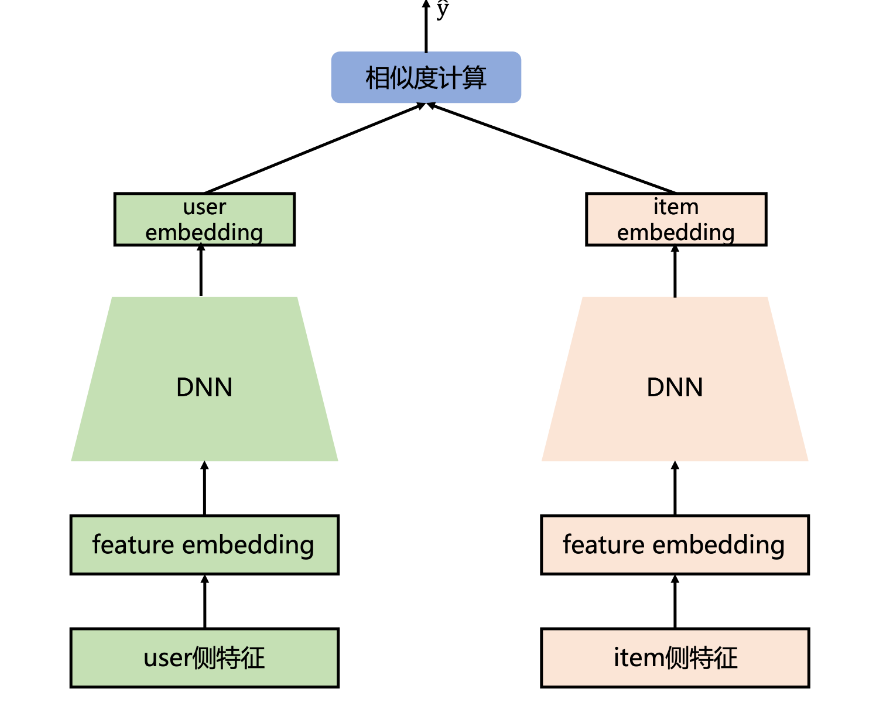
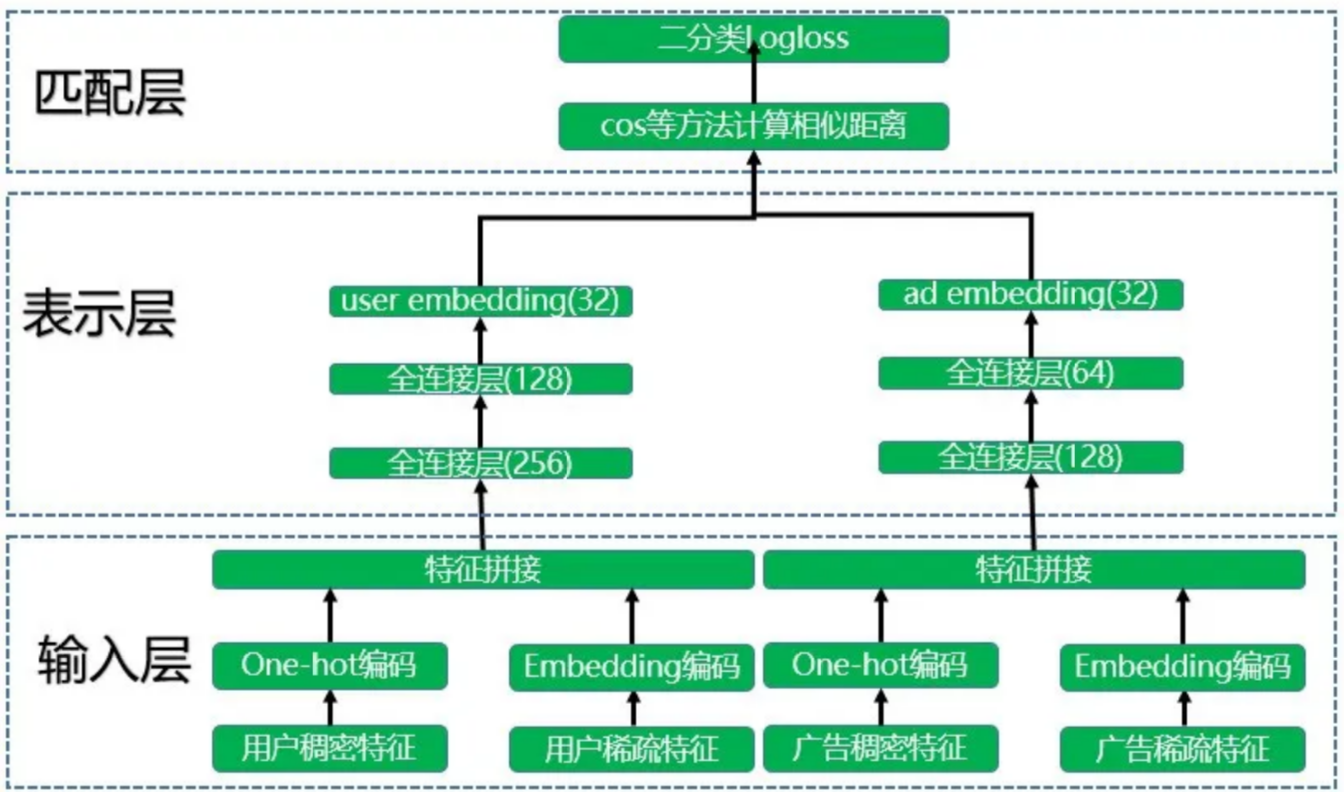
用户稠密特征:年龄、兴趣;用户稀疏特征:城市、id
过程:
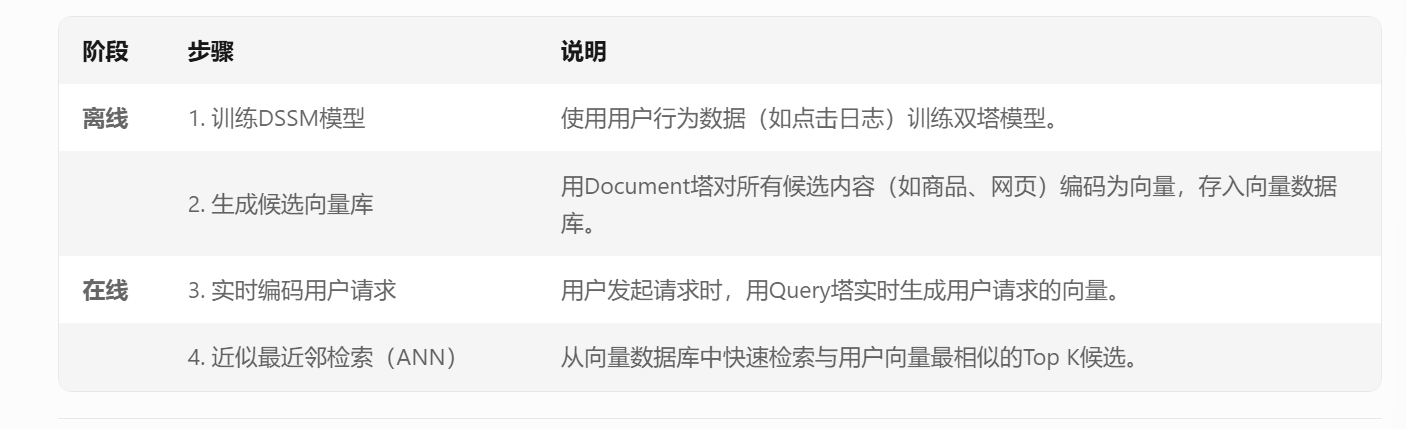
损失函数:最大化用户与正样本物品的相似度,同时最小化用户与负样本物品的相似度,损失函数是负对数似然

SASRec
预测层的输入是经过多层自注意力网络(Self-Attention Layers)和前馈网络(FFN)处理后的隐状态序列。假设用户行为序列长度为 n,模型维度为 d,则输入维度为 n×d
预测 t+1 的商品时,使用 t 时刻的隐状态,与候选物品做点乘然后经过softmax,可以得到最终的排名
损失函数即交叉熵损失(负对数似然损失)
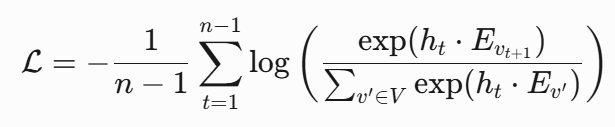
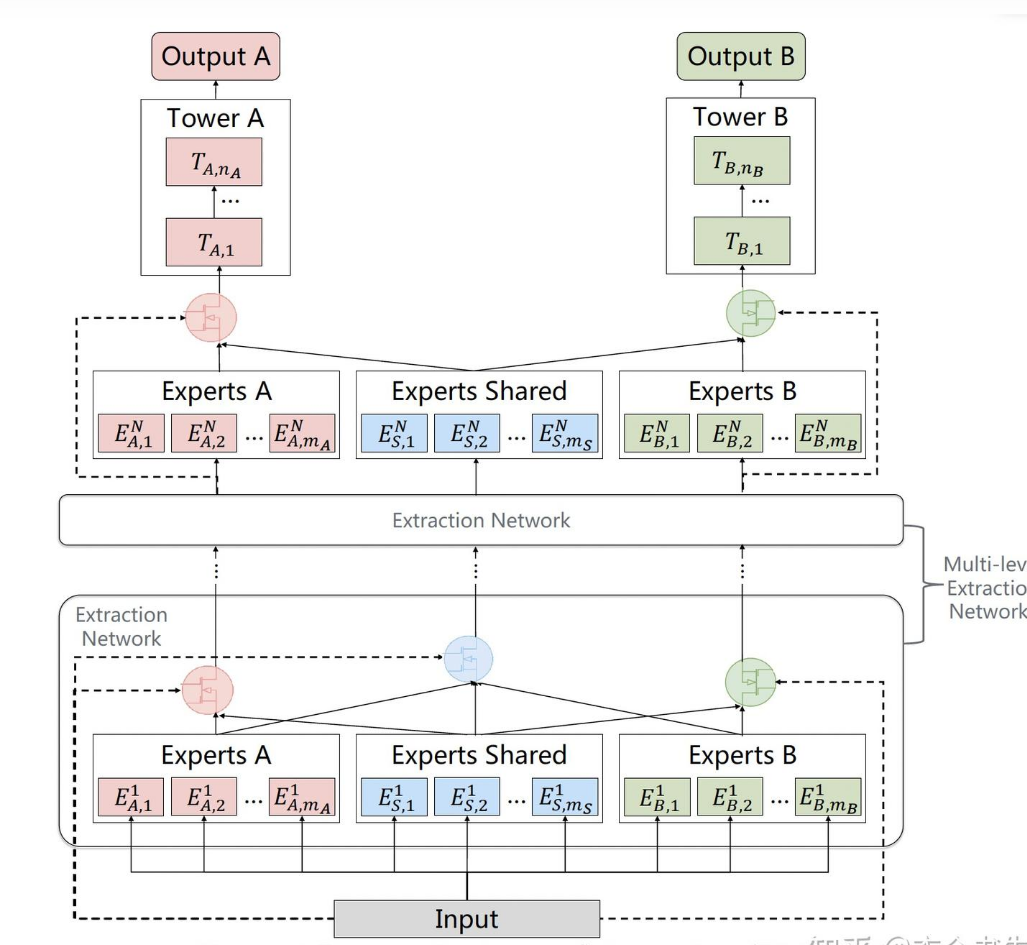
4、介绍下MMOE在推荐系统中的应用
MMOE即多门路的混合专家系统去实现一个多目标优化的效果,有几个目标,可以设置几个门路,与几个输出层
比如同时优化点击率CTR和转化率CVR(用户点击广告后完成特定行为(如购买、注册、下载等)的比例)

MMOE中存在一定的问题,1:多个任务是共享Expert专家模型的,无法捕捉到任务之间更复杂的关系。2:Expert专家模型之间没有交互,联合优化的效果有折扣
腾讯提出了PLE,针对问题1,每个任务设定了独立的Expert,同时保留了共享的Expert
针对问题2,增加了多层Extraction Network,每一层中的共享专家模块不断融入各个专家模块的信息