
1:为什么使用多头注意力,为啥不使用一个头
表达能力:多头注意力可以更好的捕捉序列中的不同信息,不同的头可以分别去关注序列中的不同内容
计算效率:如果使用一个注意力头,要达到一个比较好的效果,需要一个维度比较大的矩阵,计算复杂度高,多头注意力虽然有多个矩阵,但是是可以并行计算的,效率比较高
2:Q和K为什么用不同的矩阵生成,为啥不用相同的矩阵生成
表达能力:注意力机制,使用不同的Q,K矩阵来生成注意力向量,是为了在计算注意力得分时,可以捕捉到不同的特征,如果使用同一个矩阵生成,无法有效区分查询向量和键向量的不同特征,降低表达能力
3:计算注意力时为啥使用点乘不是加法
表达能力:点乘可以更好的体现出查询向量和键向量之间的相关性
计算效率:在矩阵计算中,点乘有着并行计算优势,计算效率更高
复杂度更低:使用加法注意力,在计算相似度(softmax里面的东西)的时候,需要引入一个额外的层,例如全连接层
4:计算注意力时,为啥需要除以dk的平方根进行缩放
梯度消失:因为在注意力计算时,用到了softmax激活函数,如果Q和K点乘的值比较大的话,softmax的值会比较小,可能会出现梯度消失的问题,所以除以d_k的平方根缓解这个问题
除以根号 d 其实本质上是把点积的方差缩至1,这样无论输入的维度是多少,都可以保证softmax的稳定
5:介绍一下Transformer中的掩码(mask)机制
两类mask,官方没有直接给出命名,有些文章里面取的是padding mask,sequence mask
训练阶段:
①padding mask,输入序列长度可能不一样,需要补0对齐或者截断,然后计算注意力的时候,这些补齐的是不需要计算了,所以在softmax前加上负无穷,让其注意力分数为0,在编码器的自注意力机制和解码器的交叉注意力机制都有
②sequence mask,训练的时候,为了实现并行计算,让训练的时候,编码器可以不关注到未来的信息
应用阶段:只用到padding mask
6:Transformer为什么需要残差连接与层归一化
先解释梯度爆炸、梯度消失、网格退化问题
梯度消失:softmax等激活函数,在值较大或较小时,变化很小,导致梯度很小,反向传播不断相乘导致梯度消失的问题
梯度爆炸:神经网络有多次连乘,不断相乘梯度可能越来越大,出现梯度爆炸的问题
网格退化问题:模型收敛的情况下,增加网络层数,性能可能反而下降
残差连接:解决网格退化的问题,残差连接本质上就是一种兜底的策略,通过将输入和输出连着一起,实现一种恒等映射的效果,确保在某一层达到最优解后,增加层数也不会导致性能下降
恒等映射:因为残差连接是将当前层的输入和输出连接在一起,神经网络会学习一个最优的函数,假设有20层的网络。只用到前10层是最优,这个时候神经网络就可以学习到,后面10层的网络输出均是0,直接与第10层的网络连接到一起是最优的,最后20层的输出,和第10层的输出,是差不多的,也就是恒等映射
层归一化:归一化可以缓解梯度消失和梯度爆炸的问题,但是因为transformer的序列长度并不全一样,batch归一化并不合适,所以选用层归一化
BatchNorm是对一个batch-size样本内的每个特征[分别]做归一化,LayerNorm是[分别]对每个样本的所有特征做归一化
在序列预测任务中,不同样本的信息差异是很重要,由于他们的归一化方式不同,BN在batchsize维度上归一化,会抹平不同样本之间的一个差异
归一化通常用于残差连接后面,残差连接将上一层的输入与输出相加,可能导致数据分布发生显著变化,归一化通过调整数据分布,提高了数据的稳定性
7:描述一下transformer中的前馈神经网络
线性变换--->relu--->线性变换
优点:提高模型的非线性表达能力(因为muti head attention中都是矩阵乘法,都是线性变换)
缺点:导致一些节点死亡(部分神经元输出恒为0)
为什么要先升维再降维
8:Transformer训练的时候学习率是如何设定的?Dropout是如何设定的,位置在哪里?Dropout 在测试的需要有什么需要注意的吗?
学习率:预热的学习率衰减,通过设定预热步数,确保学习率是先上升,后下降(可以使用线性或者余弦的衰减)
Dropout:随机让网络中的神经元不工作,然后将保留的神经元乘以一个因子,保证输出的期望不变(随机丢弃一些,剩下的比例放大)
Dropout应用位置:嵌入层的输出、注意力层的输出、残差连接的输出、前馈神经网络的输出(激活函数后)
测试时,不使用dropout
9:self-attention时间复杂度以及解决办法

为什么线性注意力可以降低时间复杂度:因为传统注意力机制里面,大头是QK的点乘和softmax操作,都是n方的时间复杂度
引入线性注意力,将softmax(QK)的运算分解了:

将复杂度从n方d,降到了nd方
10:位置编码有哪些
传统的sin、cos位置编码
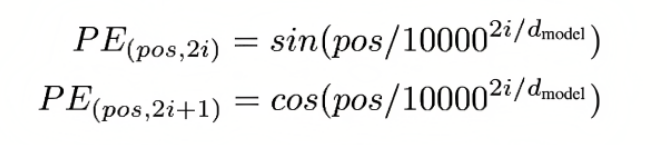

分母10000:控制波长的大小,从数学上来说,波长很短的话,靠前的特征和靠后的特征,反而会很接近
为什么sin和cos交替使用:
1、从数学特性来说,一个位置的位置编码,因为它是sin和cos交替,可以由另外一个位置的位置编码乘一个旋转矩阵(让一个向量进行旋转变换的工具)得到

2、如果只用sin或者cos,导致相邻位置,特征太像了
可学习的位置编码
11:介绍下相对位置编码与旋转位置编码
与传统的绝对位置编码不同,它不关注元素在序列中的绝对位置(如第几个词),而是关注元素之间的相对距离(如两个词相隔多远)
旋转位置编码,对输入向量进行旋转变换,将位置信息嵌入到向量中
