
Transformer其实也是一个 Encoder-Decoder 模式
其实也是由 RNN 改进而来,用 multi-head attention 机制取代了传统的 RNN 网络,传统的RNN网络需要一个时刻一个时刻的顺序输入数据,距离的依存关系需要经过多个时间步骤才能联系到一起,从而容易造成难以捕捉
Transformer 则因为其独特的多头自注意力机制,可以实现并行计算
Transformer 有三种注意力机制,多头自注意力机制实现并行处理输入+长距离序列捕捉,多头交叉注意力机制加强预测效果,交叉注意力机制更类似于 RNN 中的注意力机制,多头带掩码自注意力机制提高训练时的效率
多头注意力机制
本质上只是为了提高拟合性,在原注意力机制上的扩展
注:编码器为自注意力机制,解码器是带掩码自注意力机制的交叉注意力机制,都是多头,后面会分别解释
注意力机制中,Q、K、V 各用一个矩阵得出,多头自注意力机制用多个矩阵
以两个时间步的多头自注意力例子来介绍:
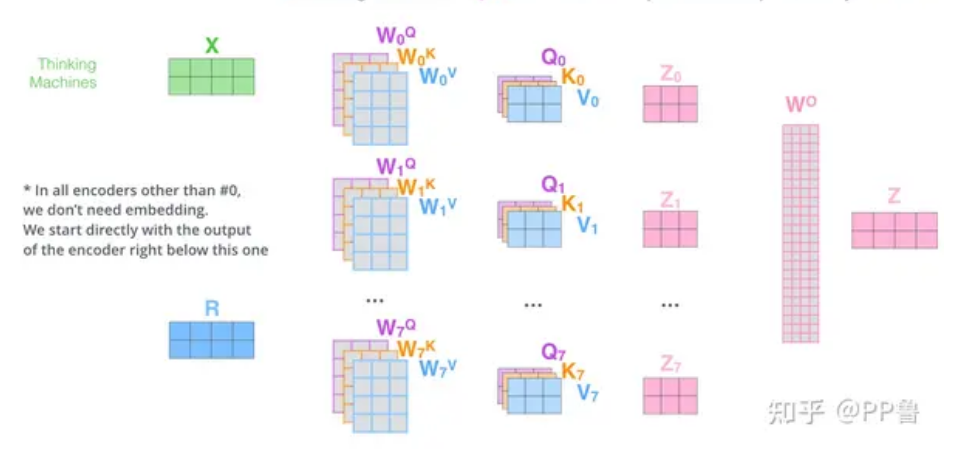
X 的两行,分别代表两个时间步的输入,在 RNN 中实际上这两行是分开处理的(先处理第一行再处理第二行),但是 Transformer 中可以并行处理(多头自注意力的作用)
为了方便,这里的例子一个输入用了4维的向量表示,实际上向量一般是 256 或者 512 维,
注:我觉得K、Q、V 矩阵的序列长度都是一样的(虽然也有资料说可能不一样,但是我不理解,不明白为啥不一样还可以做点乘)
在自注意力机制中,X 只能得到 Z0 到 Z7 的其中一个,但是在多头注意力机制中,X是将Z0 到 Z7 聚合
聚合后的矩阵乘上一个 Wo 得到最终的输出
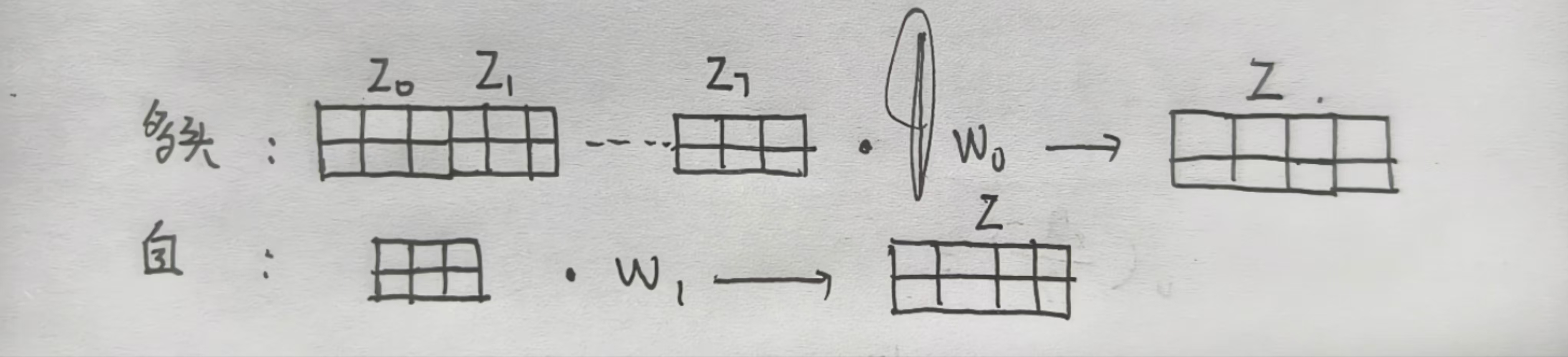
Transformer
在这一部分,我先宏观的叙述下 Transformer 的预测过程,再微观的去介绍 Transformer 的细节
宏观框架
用一个英译中的例子来说明 Transformer ,knowledge is power 代表三个时序的数据,如果在 RNN、LSTM 中,这三个单词是分别顺序处理的,但是在 Transformer 中,这三个单词是同时处理(预测的时候还是顺序预测,但是训练的时候因为掩码注意力机制可以一起预测出)
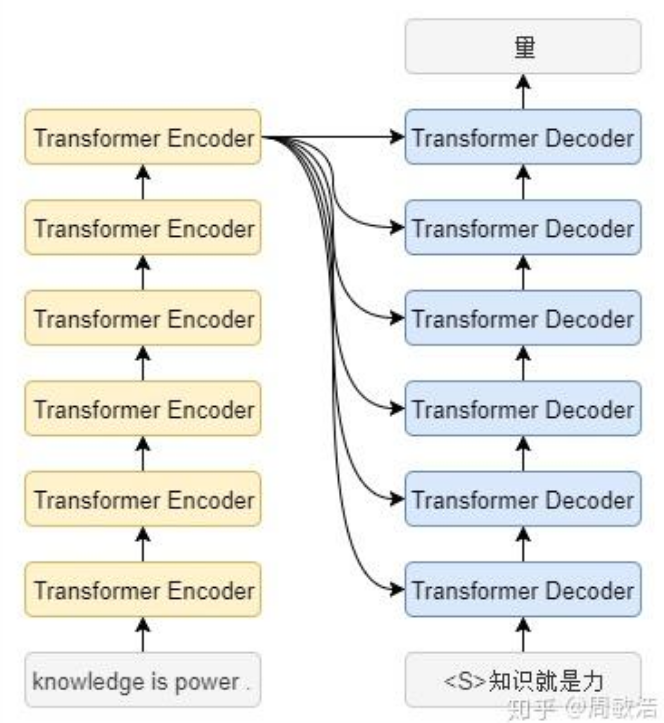

Transformer 是很多个编码器,解码器堆叠而成,如图展示的是各6个,也是论文中原版结构
第一个编码器的输入是词向量,而后面的编码器的输入是上一个编码器的输出
第6个编码器的输出,会传递给每一个解码器
预测的时候,还是顺序一个个预测,但是引入了 Masked Multi-Head Attention,可以去并行训练(把答案一起输进去,预测第几个字就把 该字即该字后面的 屏蔽)
微观细节
具体而言,Transformer 以如下细节实现
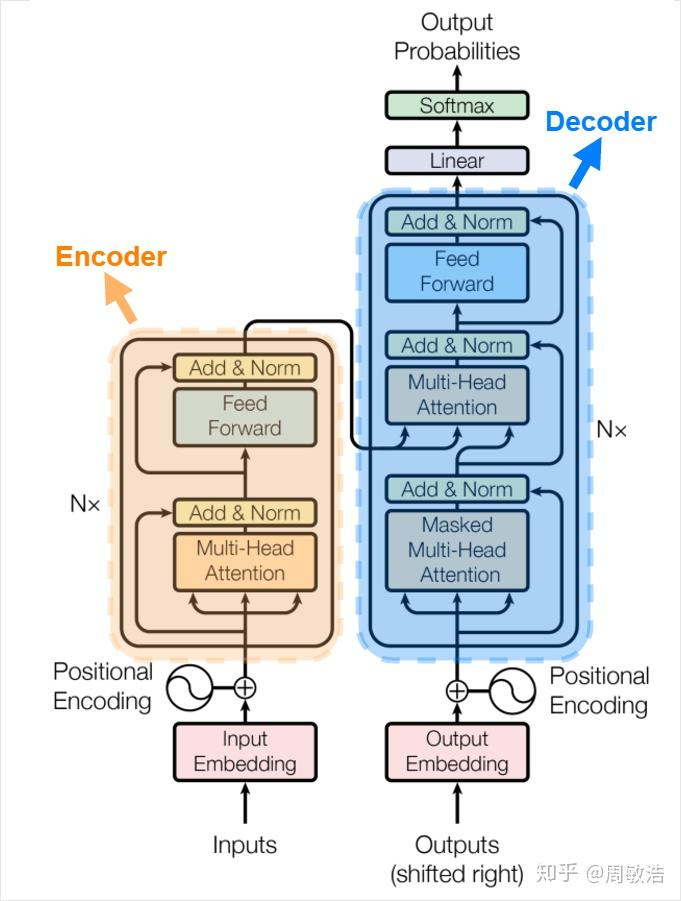
编码器部分
Positional Encoding
由于 RNN、LSTM 天生的递归结构(输入是按时间顺序处理),可以天然捕获顺序信息,但是 Transformer是顺序处理输入数据的,无法捕捉序列的顺序,于是引入了 Positional Encoding ,即位置编码去解决这个问题:
如原始论文的正弦和余弦位置编码,比如对第 i 个向量进行位置编码
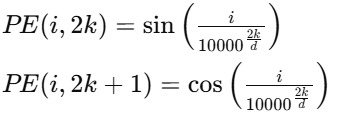
第 i 个向量第0维,就用 PE(i,0) 计算,0是偶数,所以用正弦,同理,第 i 个向量第1维,就用 PE(i,1) 计算,1是基数,所以用余弦
得到所有输入的位置向量后,再与对应的原始输入相加,生成最终的输入表示
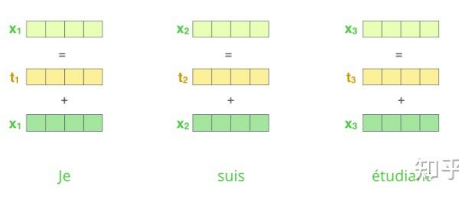
正弦和余弦的特点使得短距离的单词之间拥有较小的编码值差异,而长距离的单词则拥有更大的差异
实际上除了正弦和余弦位置编码,也可以用可学习的位置编码,即将位置编码当成网络参数去训练
Add & Norm
Add & Norm 即残差连接与层归一化
残差连接是将当前层的输出与输入相加的一种技术,缓解神经网络在训练过程中可能出现的梯度消失或梯度爆炸问题,在 Transformer 编码器中,残差连接被应用于每个子层(如自注意力层和前馈神经网络层)的输出
层归一化是对每一层的输出进行标准化,以改善训练的稳定性和加速收敛,将每一层的输出减去其均值,并除以标准差
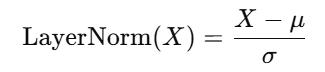
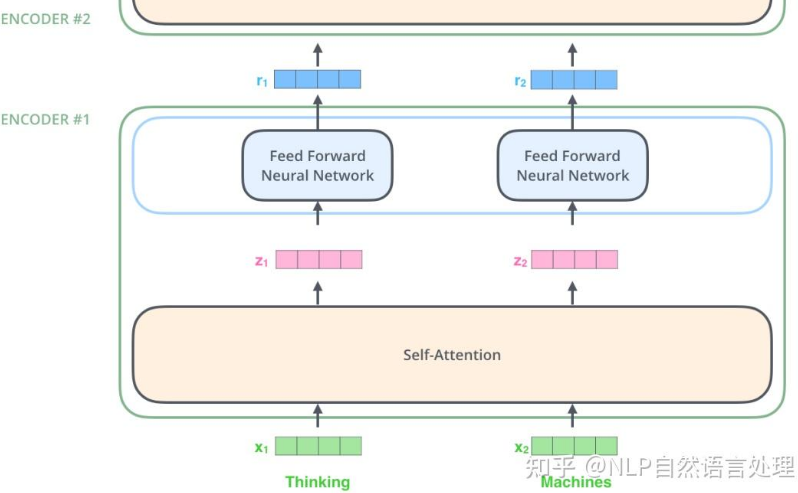
比如编码器中的多头注意力机制的输出,从原来的 SelfAttention(X) 变为了 OutputAttention

Feed-Forward Neural Network
每个编码器层内都包含一个前馈神经网络(Feed-Forward Neural Network),它由两个线性变换和一个激活函数(通常是 ReLU)组成
第一个线性变换将输入的向量映射到一个较高维度的空间(通常是两倍于输入的维度)
然后通过 ReLU 激活函数
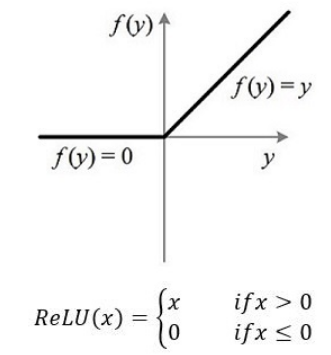
然后通过另一个线性变换,将向量映射回原始维度
解码器部分
Masked Multi-Head Attention
在训练阶段起到可以并行输出预测结果的作用,提高训练效率
实际上 Transformer 在预测过程中,每个字都是顺序预测的,先预测 “知”,然后迭代作为输入,预测出 “知识”,然后迭代作为输入,预测出 “知识就”,不断顺序递归迭代
但是训练的时候,可以把 “知识就是力量” 全部传给它,预测 “知识就” 的时候,把 “力量” 给它屏蔽了
在标准的自注意力机制中,所有位置的词都可以相互影响,为了保证预测顺序性,解码器的自注意力加上了遮蔽,这样在计算每个位置的词时,只能使用当前及之前的词的信息
在实现上,这通过上三角矩阵掩码来实现,未来的词(即预测的词后面的词)在计算注意力时是不可访问的。具体来说,模型的注意力权重矩阵中,当前时间步之后的词的权重被设置为零,这样它们在注意力计算时就不会被考虑

比如这样一个掩码,与 score 矩阵相加,让未来的词汇得分变为负无穷,从而让未来的词汇权重为0(softmax 负无穷为0),进而达到屏蔽效果
在预测阶段,给这样一个预测例子:

ok,如果没有带掩码的注意力机制,那你第三步预测的y1、y2,与前面的y1、y2,可能完全不一样!!因为第三步预测y1、y2,能直接看到自己未来!这是不允许的
预测阶段我们希望是增量更新的,对于重复的预测结果,我们希望每一次都是一样的
Multi-Head Attention
然后 Masked Multi-Head Attention 的输出(作为Q)与最后一个编码器的输出(作为K)会一同输入到一个 Multi-Head Attention 层,这是一个多头交叉注意力层
后面就是重复劳动了,Masked Multi-Head Attention 在这一时刻的输出有 n 行向量,也会同样预测 n 个词
但是实际上,在真正代码中,我们常常只使用最后一行向量,去预测出最近的结果(反正已经预测出的结果又不会变)
