SAC是一种actor-critic架构为基础的策略学习的强化学习
并不是基于策略梯度来更新策略网络,而是通过最大化奖励和熵来更新策略网络,是一种off-policy的强化学习
引入了最大熵和一个可学习的调节参数alpha来平衡探索与利用,设定一个熵阈值,如果小于阈值,增大alpha,提高探索
引入了soft策略评估和soft策略提升
同时还引入了两个Q网络和两个目标网络,减少了TD算法带来的更新的影响
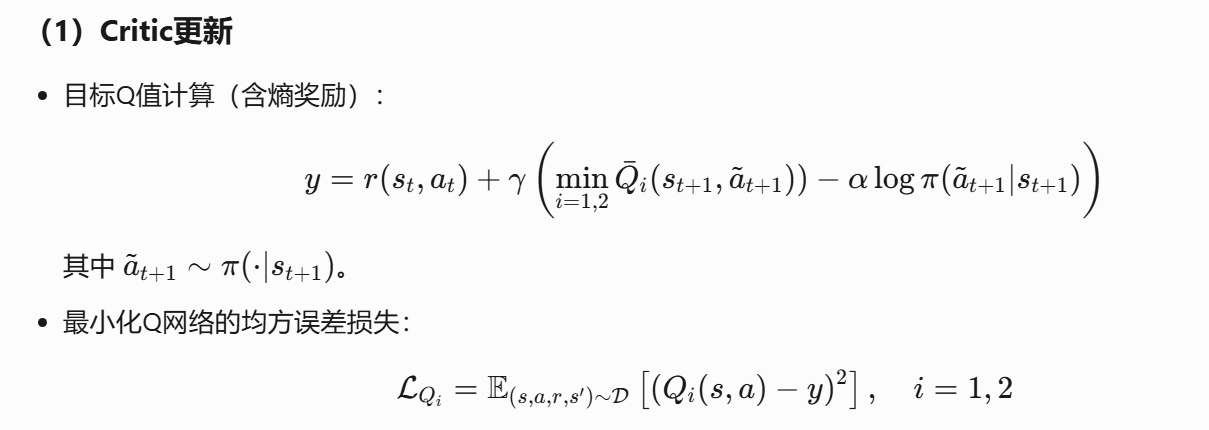
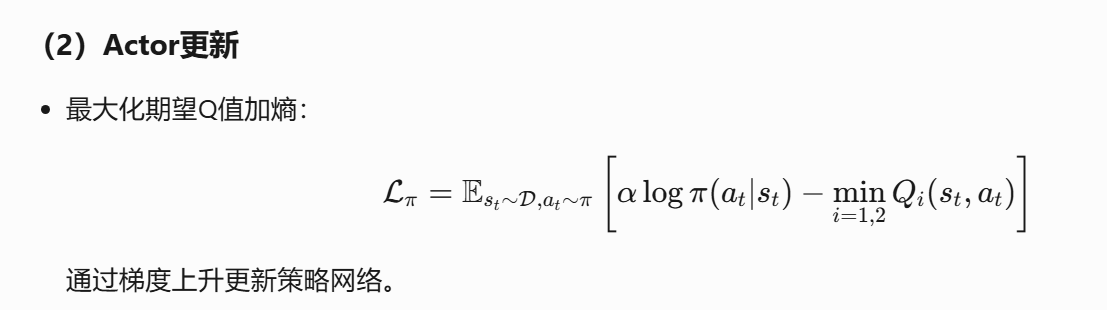



Hi,早上好!欢迎来到Cxy的小破站!