
时序预测任务:当前的输出与前面的输出也有关,即xt = f(xt-1, xt-2......xt-n),f 即时序神经网络
传统RNN:n个输入n个输出、n个输入1个输出
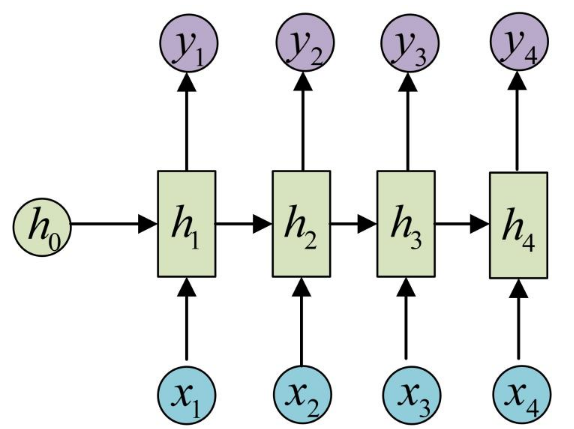
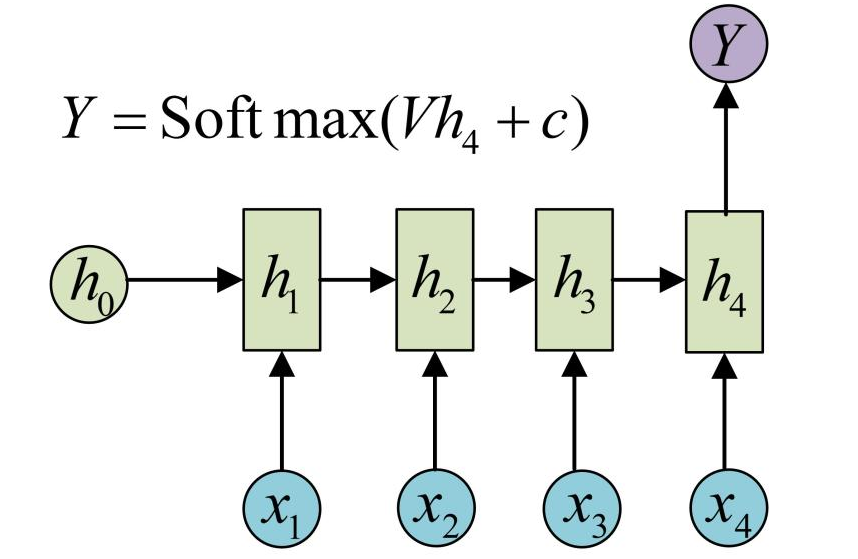
以n个输入,1个输出为例,上图是一个经典的 RNN 神经网络架构,输入(x1,x2,x3,x4)输出一个预测值y
具体而言,利用公式 ht = f(U * xt + W * ht-1 + b) 从 h1 开始迭代计算出 h4,再通过 y = g(V * h4 + c)计算出最终结果 y,其中 U,W,b,V,c 是神经网络训练学习出的参数,让损失函数尽量小的参数,g 是激活函数,如图中的Softmax
初始化h0,输入x1,得到h1
利用h1,输入x2,得到h2
利用h2,输入x3,得到h3
利用h3,输入x4,得到h4
利用h4,输出最终的y值
RNN变体:n个输入,m个输出
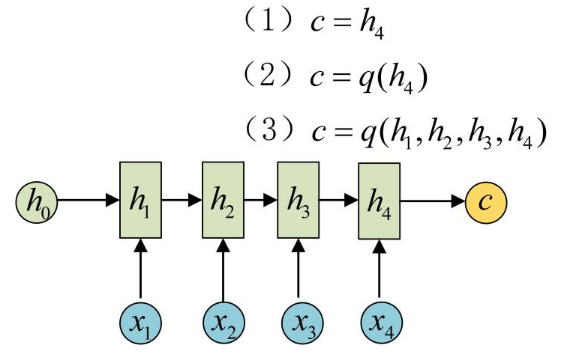
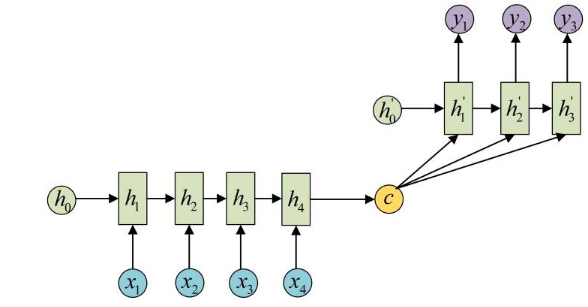
如上图所示,采用经典的 Encoder-Decoder 结构,即拥有两个 RNN 网络,一个叫Encoder,一个叫Decoder,将(x1,x2,x3,x4)编码为(h1,h2,h3,h4) ,再由编码后的(h1,h2,h3,h4)计算出c,c 可以有多种方式计算,如图中的(1)、(2)、(3)均可,作为 Decoder 网络的输入,然后Decoder 网络再进行预测
注:实际上 h’0 通常是 h4
缺点:实际上Decoder 网络只用到了一个输入 c ,无法完全表达整个序列的信息,体现不出时序的特点
修改,引入注意力机制,将 c 变为 c1, c2, c3,作为Decoder 网络的输入:
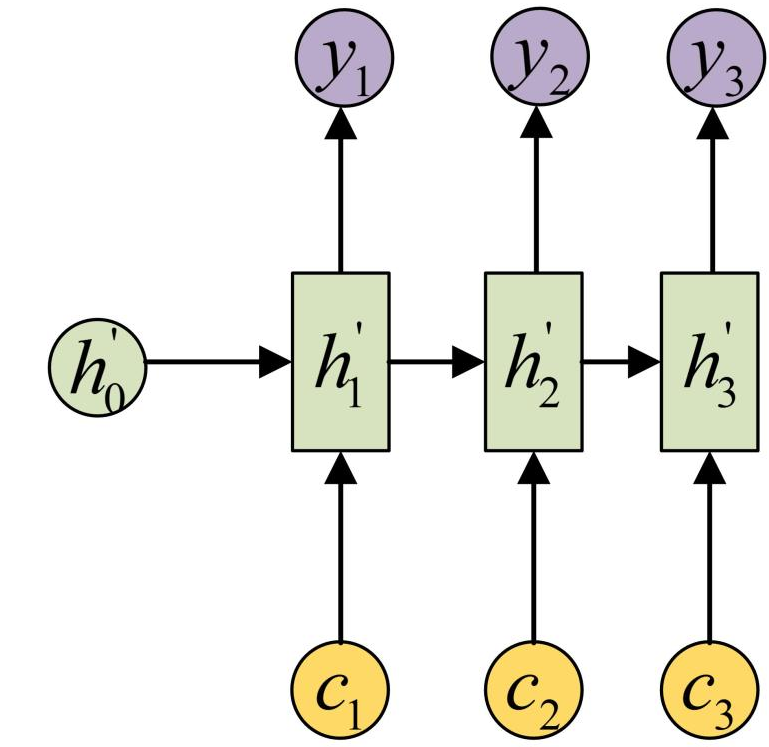
其中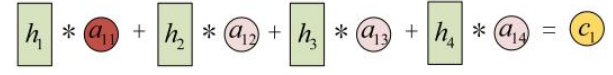
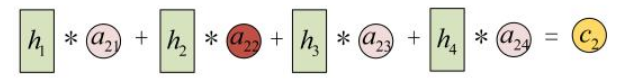
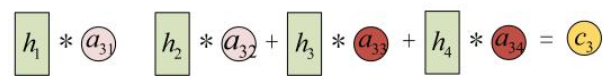
a11、a12 ...... a34 也是神经网络训练学习出的参数(也有直接用点积计算的,详见注意力机制章节)
