
强化学习可以分为在线策略强化学习,离线策略强化学习,离线强化学习
无论是在线策略(on-policy)算法还是离线策略(off-policy)算法,都有一个共同点:智能体在训练过程中可以不断和环境交互,得到新的反馈数据。二者的区别主要在于在线策略算法会直接使用这些反馈数据,而离线策略算法会先将数据存入经验回放池中,需要时再采样
但是离线强化学习是在智能体不和环境交互的情况下,仅从已经收集好的确定的数据集中,通过强化学习算法得到比较好的策略
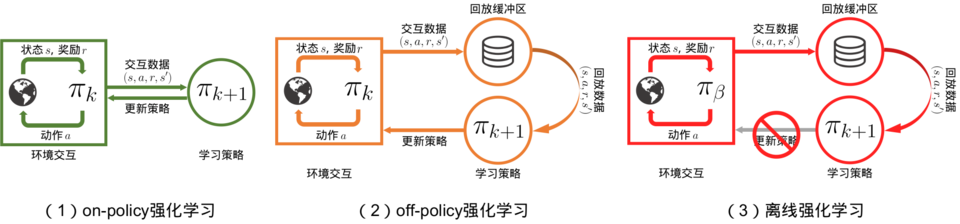
从第一映像来看,离线策略强化学习的算法可以直接用于离线强化学习,实则不然
有人做了这样一个对比实验
实验1:使用 DDPG 算法训练了一个智能体,并将智能体与环境训练过程中的所有数据都记录下来,再用这些数据训练离线 DDPG 智能体
实验2:在线 DDPG 算法在训练时每次从经验回放池中采样,并用相同的数据同步训练离线 DDPG 智能体,这样两个智能体甚至连训练时用到的数据顺序都完全相同
实验3:在线 DDPG 算法在训练完毕后作为专家,在环境中采集大量数据,供离线 DDPG 智能体学习
结果如下:
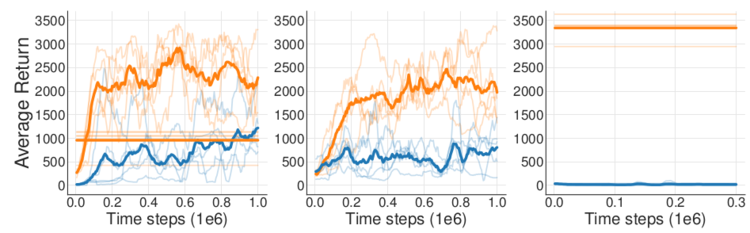
离线策略算法不能直接迁移到离线强化学习中的原因主要是外推误差
外推误差:当前策略可能访问到的状态动作对与从数据集中采样得到的状态动作对的分布不匹配而产生的误差
在离线策略强化学习中,即使训练是离线策略的,智能体依然有机会通过与环境交互及时采样到新的数据,从而修正这些误差。但是在离线强化学习中,智能体无法和环境交互
所以离线强化学习的一个重点在于:当前的策略需要做到只访问与数据集中相似的(s,a)数据
