
ROBUST REINFORCEMENT LEARNING ON STATE OBSERVATIONS WITH LEARNED OPTIMAL ADVERSARY
中文:基于学习的最优对手的状态观测下的稳健强化学习
解决问题:作者提出了一种交替训练框架(ATLA),在训练过程中在线训练对手和代理,强化学习代理通过学习最优对抗者来最大化自身鲁棒性
对手:破坏RL代理的状态观测,最大化地降低代理的奖励
ATLA
首先固定智能体的策略,优化对手的策略,使其找到能使智能体表现最差的攻击
然后固定对手的策略,优化智能体的策略,使其在这最恶劣的环境中学会最优的对策
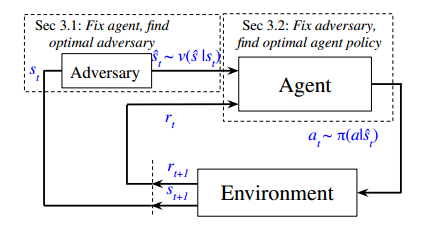

智能体特点
引入历史信息,将LSTM应用到RL智能体的策略网络,使得策略不仅仅依赖当前的状态观测
对策略函数进行正则化,使得智能体在面对扰动后的状态观测时,策略输出的变化尽可能小
Efficient Adversarial Training without Attacking: Worst-Case-Aware Robust Reinforcement Learning
中文:无攻击的有效对抗性训练:最坏情况感知稳健强化学习
解决问题:提出了一种新的鲁棒训练框架
不确定环境下,仅仅考虑自然状态下的回报是不够的,提出一种最坏攻击贝尔曼算子,估计策略在遭受攻击时的最坏情况动作值(避免通过大量样本显式学习最优攻击者)
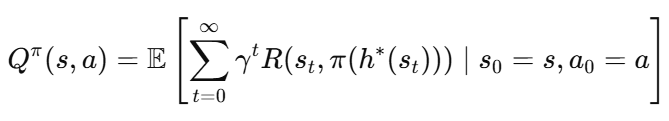
critic网络引入最坏攻击Bellman算子进行训练,策略优化时,使用对抗性攻击下的最坏回报代替了自然状态下的未来回报
引入基于价值的状态正则化,对状态的重要性进行度量,从而对策略施加不同程度的正则化
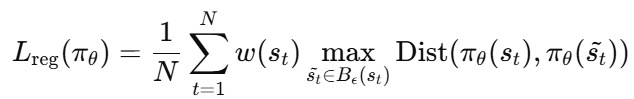
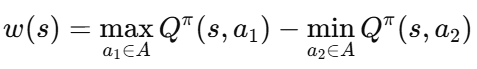

est:最坏攻击critic网络的损失函数(估计最坏情况动作值)
wst:策略优化的损失函数
reg:状态正则化的损失函数
