
1:在RLHF中,PPO、DPO、GRPO有什么区别,loss是什么样的、各自的优缺点是啥
共同点:三者都属于策略优化的方法
PPO(近端策略优化):是一种在线强化学习的方法(但是因为限定了更新的幅度,所以可以利用部分之前的数据),构建奖励模型,依赖Critic模型和奖励来估计优势函数,不断交互迭代,最大化奖励来优化策略模型
DPO(直接偏好优化):是一种离线的学习方法(监督学习),直接利用偏好数据训练策略,不需要奖励模型,
GROP(组相对策略优化):是一种PPO的加强版本,移除了Critic模型,对同一输入生成多个响应,计算组内奖励的均值和标准差,以此动态调整优势值
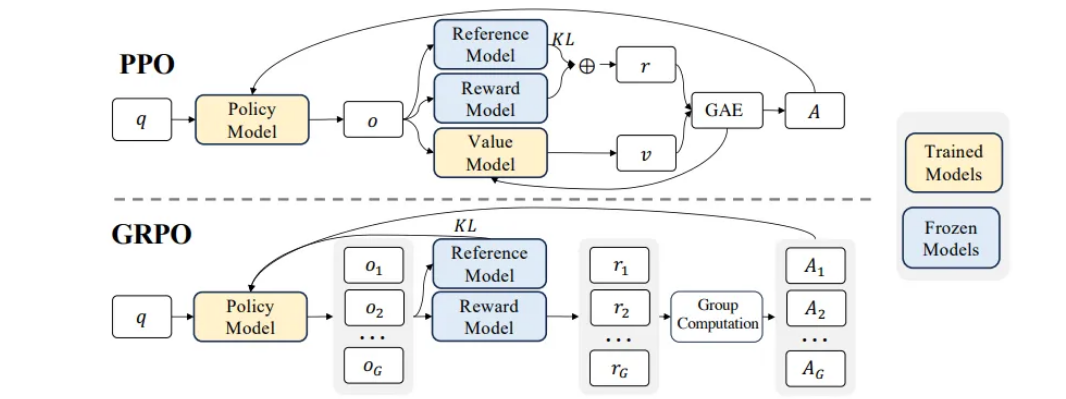
PPO_loss:ppo将KL散度(在训练模式下,将prompt+answer分别输入到actor mode和ref model,用KL散度来衡量 ref model和actor mode输出的差别)放入了奖励函数当中

DPO_loss:x是输入,y_w是优于y_l的回答,sigma是sigmoid函数

GROP_loss:DRPO将KL散度放入了损失函数当中(降低了优势函数计算的复杂性)

PPO优点:稳定性强,通过限定策略更新幅度,使训练更稳定,不会太过偏移预训练模型
PPO缺点:计算复杂率高,若奖励模型设置不恰当,可能会其反作用
DPO优点:计算效率高,无需奖励模型(不需要和奖励模型交互)
DPO缺点:没有KL散度约束模型与基础参考模型(即初始SFT模型)的差异,可能导致模型太过偏离基础参考模型,出现过拟合或者太过偏向于偏好答案,降低了答案的多样性
GROP优点:继承了ppo的优点,稳定性强,通过整合多个观测值完成训练,质量更好,移除了价值模型并简化了优势估计,其计算效率更高
GROP缺点:复杂度高,参数量大,训练难度高,若奖励模型设置不恰当,可能会其反作用
引入KL散度作用:通过限制模型与参考模型的差异,1、防止模型太过偏离基础参考模型(可能出现过拟合);2、防止策略模型只生产单一的高奖励答案,保证了答案的多样性
GROP中,Aˆi,t = (ri - mean(r)) / std(r),奖励减平均值除标准差,来估计相对优势的
2:为什么要引入目标网络
无论是DQN算法,还是Actor-Critic网络,他们都涉及最优动作价值函数的估计和动作价值函数的估计,分别使用TD算法和SARSA算法来更新,这两个算法有个问题,就是用自己估计的值,来不断更新自己,是一种自举的方法,这种方法可能会导致偏差的传播,出现高估的问题,引入目标网络,用目标网络的值来更新自己,提高网络性能
3:介绍下DQN、DDQN、Dueling DQN的区别
DQN:也就是最基本的基于价值的深度强化学习,通过估计最优动作价值函数实现优化目标
DDQN:引入了目标网络,环境DQN中自举产生的高估问题
Dueling DQN:将动作价值函数分解为状态价值函数和动作优势函数,可以分别去关注状态的整体价值和动作的整体优势,提高学习效率
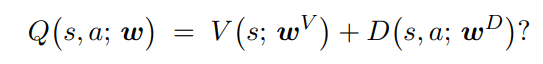
并不能直接这样,这样可能会导致Q值的不稳定,不同的V和D可能有相同的Q值估计,在V+D的基础上,减去D的最大值或者减去D的均值

4:什么是GAE广义优势估计
GAE是未来所有TD误差的加权和,权重随步数呈几何衰减
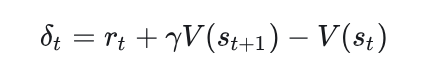
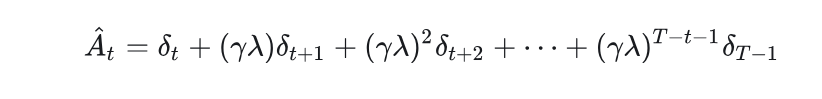
GAE是把TD的思想,融入了优势函数的估计当中
为什么不用奖励,而是用优势估计:动作优势函数实际上是动作价值函数减去状态价值函数,换个角度看是对动作价值函数减去了一个基线,降低了方差,提高收敛效率
5:蒙特卡洛,TD,GAE对比
蒙特卡洛完整轨迹,无偏估计,低偏差,高方差
TD算法一部分真实值,一部分估计值,高偏差,低方差
GAE是通过对未来所有TD误差的加权和来估计动作优势函数,通过调节参数lamba平衡方差与偏差
6:DDPG、AC的对比和分析
AC是在线策略强化学习(训练的策略和采集数据的策略是同一个策略),不能用经验回放这样的存储机制,样本利用率低
DDPG是离线策略强化学习,能利用经验回放,可以重复利用旧数据,样本利用率高
AC是从策略分布中随机采样得到最后的动作,DDPG是确定性的输出最后的动作
AC的目的是不断迭代当前策略,不断提升Critic网络的评价,这也是他是on-policy强化学习的原因
DDPG的目的是直接找到最优策略函数,有点类似与DQN,DQN是找到最优动作价值函数,DDPG是优化actor网络逼近最优策略函数,间接让critic网络逼近最优动作价值函数,因为他不涉及当前策略,所以是off-policy
7:AC、A2C、A3C的区别和改进
AC用动作价值函数来更新策略网络
A2C将动作价值函数替换为了动作优势函数,降低了方差,方差小,收敛更快
A3C只是在A2C的基础上引入了异步训练和多步回报
8:TD3和DDPG的区别
尽管DDPG使用了目标网络(Critic和Actor都有目标网络)来缓解高估,但是其实高估仍然严重的
TD3使用了两个Critic(同样对应两个Critic的目标网络),利用小的Critic估计值来计算TD目标
在Critic网络不准确的时候更新Actor网络,可能导致Actor网络训练不稳定,所以TD3延迟了Actor网络的更新(更新多次Critic网络对应更新一次Actor网络)
在目标动作中加入噪声(如高斯噪声或者截断正态分布噪声),使训练更平滑稳定,防止Critic网络拟合到局部峰值
9:SAC与AC网络的优势
在最大化奖励的基础上,最大化策略的熵
使用了两个Critic网络来逼近动作价值函数,利用小的Critic估计值来计算TD目标,降低高估问题
引入熵正则化,提高了模型的探索能力
引入自适应调节的熵权重系数,平衡探索与利用(设定一个目标熵,小于目标熵,增大alpha,提高探索)
10:TD3、SAC、PPO优缺点对比
TD3是确定性策略,相较于引入最大熵的SAC,探索能力更低,在奖励稀疏的任务场景中更容易陷入局部最优
SAC是off-policy的强化学习算法,而ppo是on-policy的强化学习算法(但是因为ppo限制了更新幅度,所以可以用多步采样,即可以利用部分旧数据),数据利用率低,在自动驾驶这样场景数据不足的任务下,ppo效果不好
11:什么是马尔可夫决策
满足马尔可夫性质的一个决策过程,也就是无记忆性,未来状态只取决于当前状态与动作
马尔可夫决策过程可以用马尔可夫五元组来表示,状态集合,动作集合,状态转移方程,奖励函数,折扣因子
12:什么是贝尔曼方程
通过递归去求解值函数的一个方程
比如说计算状态价值函数,在取期望的前提下,用当前的奖励+下一个状态的状态价值函数来计算当前状态的状态价值函数
13:为什么有些是on-policy强化学习,有些是off-policy强化学习
on-policy:训练时,采集数据用到的策略,和需要训练更新的策略,是同一个策略
off-policy:训练时,采集数据用到的策略,和需要训练更新的策略,不是同一个策略
就拿SARSA算法来说,QAC也是一样的道理,他们估计的是当前策略的动作价值函数,是当前策略,所以数据来源和需要训练的策略需要是同一个
拿Q-learning来说,DDPG也是一样的道理,他们逼近的是最优动作价值函数,和策略无关,所以数据来源和需要训练的策略不需要是同一个
14:off-policy强化学习能不能只用以前的数据
off-policy强化学习,是离线策略强化学习,不是离线强化学习,并不能只利用旧的数据,还会不断与环境交互补充新数据
外推误差:对从未见过的状态-动作对价值估计不准确
15:离线强化学习和模仿学习的区别
模仿学习通常用到的是一些专家数据,但是离线强化学习可能大部分是一些次优数据
离线强化学习是有奖励这一概念的,模仿学习没有
离线强化学习目的仍然是学习一个策略,最大化奖励,模仿学习更像监督学习,最小化策略与专家策略的差异
16:强化学习离散动作空间和连续动作空间
1:修改actor网络输出结构,2:修改critic网络的输入与输出结构,3:修改Q值的计算,4:修改最大熵的计算
离散动作空间通常只有一个网络输出层(直接输出每个动作概率),把整个网络当成策略函数,求导时直接反向传播即可
连续动作空间有两个网络输出层,即有两个函数,通常是均值和方差对数,不用标准差是因为标准差一定是非负的,求解的时候有约束,可能会求解困难,直接采样不能反向求导的,用一个重参数化的做法,把这两个函数重参数化组成一个的新函数近似为策略函数,这样是可以求导的
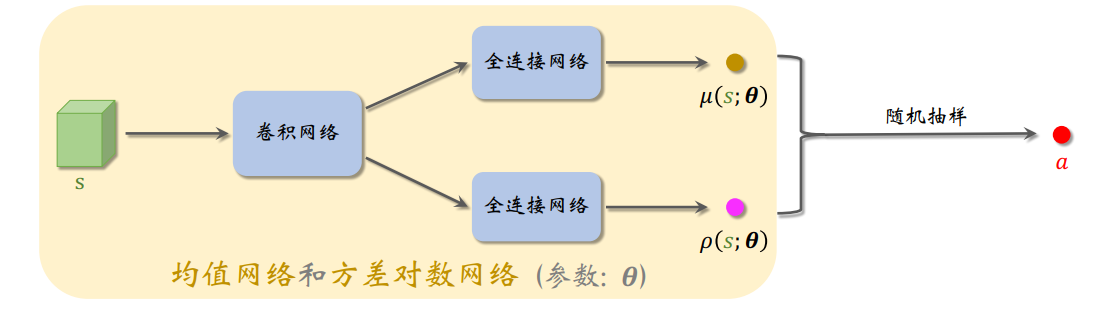
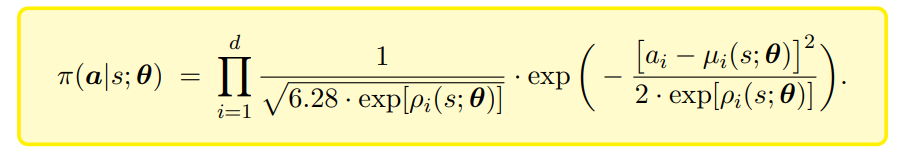
还需要修改Critic网络的结构,连续动作空间通常是状态和动作都作为输入,然后输出一个评价值,离散动作空间的话只用输入状态,给出所有动作的评价值(更高效)
计算Q值的时候,离散动作空间是用动作概率向量乘Q值向量,连续动作空间直接用目标网络输出的值
计算熵的时候,离散动作空间是对每个动作概率求log然后与动作概率向量相乘,连续动作空间是算重参数化构建的新函数取这个动作的对数概率
17:DuelingDQN和A2C分别怎么处理优势函数的
Dueling DQN 是将最优动作价值函数分解成最优价值函数和最优优势函数
AC网络中,用随机梯度来对策略梯度的一个近似,引入基线,均值是不变的,但是方差降低了,提高收敛性
A2C将状态价值作为基线(将原本的动作价值函数换为动作优势函数):
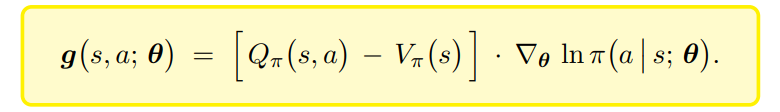
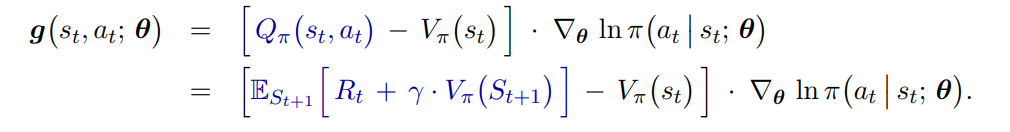
18:SAC的正则化和PPO正则化有啥区别
SAC的核心目的是最大化累计奖励和策略熵
所以SAC的状态价值函数是soft状态价值函数,需要包含未来时刻的奖励和策略熵:
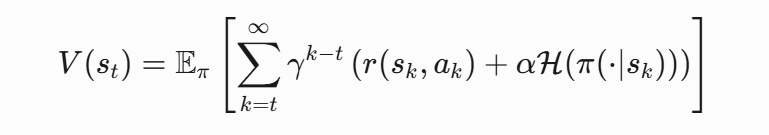
Q函数的迭代,是包含v的,所以Q函数的更新,也会受到策略熵的影响,即soft策略评估
同样的,策略网络的损失函数里面,也有个熵项,也会受到策略熵的影响,即soft策略提升
PPO里面,仅仅只是放在策略更新的损失函数里面,起一个正则化项,避免过早收敛到局部最优
而且,SAC里面熵调节参数是自动调节,PPO是手动的
19:SAC-Lag
一种带约束的强化学习办法,通过引入动态调整的拉格朗日乘子,将约束动态整合到目标函数当中


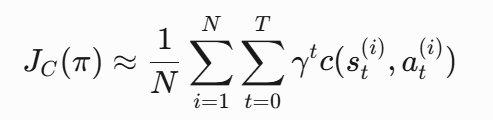
拉格朗日乘子更新:

20:介绍下cql强化学习
分布偏移指的是训练数据集中的数据分布与实际决策策略下环境反馈的数据分布之间的差异(进一步带来外推误差)。这种差异可能导致学习到的策略在实际应用中表现不佳,因为该策略是在一个与实际环境不完全相同的数据分布上学习得到的,离线强化学习上尤其严重

是一种离线强化学习,通过保守估计q值,降低离线强化学习中分布偏移,外推误差严重这些影响
外推误差:因为next_action的Q值估计时,next_action可能从未见过,导致估计有误差,种误差会通过Bellman更新不断传播,最终导致策略性能下降
在传统的Q值估计的目标函数上,引入一个正则化项,提出一种保守的估计

21:DDPG是确定性的,怎么解决这个确定性的问题(即无探索)
给动作添加噪声
使用噪声网络
引入熵正则化
22:DQN的缺陷
高估,引入目标网络
依赖greedy策略探索,不够有效,引入噪声网络
无法适应连续动作空间
只估计Q值无法关注到状态的整体价值和动作的优势,把最优动作价值函数分解成最优价值函数和最优优势函数
传统的经验回放样本利用率低,引入优先经验回放,TD误差越大的,优先级越高
23:什么是噪声网络
把原本神经网络需要学习的参数,换为可学习的均值和标准差,然后再引入从标准正态分布中提取的噪声
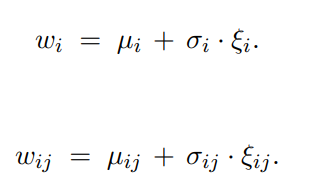
训练完成后噪声为0
