
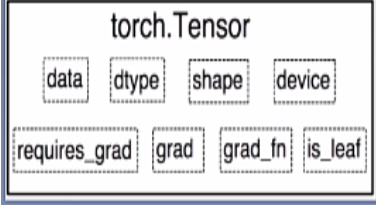
张量有以上几个属性

这是pytorch中的梯度计算图:y = a * b = (x + w) * (w + 1),若此时, x=2, w=1, y对x求导是2,y对w求导是5
叶子节点:x,w,也是用户创建的节点,所有梯度的计算都要依赖叶子节点,梯度反向传播结束之后,非叶子节点的梯度都会被释放掉
import torch
w = torch.tensor([1.], requires_grad=True) #由于需要计算梯度,所以requires_grad设置为True
x = torch.tensor([2.], requires_grad=True) #由于需要计算梯度,所以requires_grad设置为True
a = torch.add(w, x) # a = w + x
b = torch.add(w, 1) # b = w + 1
y = torch.mul(a, b) # y = a * b
y.backward() #对y进行反向传播
print(w.grad) #输出w的梯度
#查看叶子结点
print("is_leaf:\n", w.is_leaf, x.is_leaf, a.is_leaf, b.is_leaf, y.is_leaf)
#输出为True True False False False,只有前面两个是叶子节点
#查看梯度
print("gradient:\n", w.grad, x.grad, a.grad, b.grad, y.grad)
#输出为tensor([5.]) tensor([2.]) None None None,因为非叶子节点都被释放掉了
若想保存非叶子节点梯度使用 retain_grad()
a.retain_grad()
#保存非叶子结点a的梯度,输出为tensor([5.]) tensor([2.]) tensor([2.]) None Nonegrad_fn 的作用是记录创建该张量时所用的方法,例如y在反向传播的时候会记录y是用乘法得到的,所用在求解a和b的梯度的时候就会用到乘法的求导法则去求解a和b的梯度
# 查看 grad_fn
print("grad_fn:\n", w.grad_fn, x.grad_fn, a.grad_fn, b.grad_fn, y.grad_fn)
#上面代码的输出结果为
grad_fn:
None None <AddBackward0 object at 0x000001EEAA829308> <AddBackward0 object at 0x000001EE9C051548> <MulBackward0 object at 0x000001EE9C29F948>
pytorch中,每次前向传播都会动态构建计算图,如果有两个损失函数,涉及到同一个计算图,需要保留,例如Gan中 disc_loss.backward(retain_graph=True),两个损失都用到了disc_fake
反向传播前,梯度计算所需要的变量不能原地修改
# 判别器判别
disc_real = discriminator(obs_real)
disc_fake = discriminator(obs_fake)
# 判别器损失
disc_loss = discriminator_loss(disc_real, disc_fake)
# 更新判别器
discriminator_optimizer.zero_grad()
disc_loss.backward(retain_graph=True)
# 必须有,因为两个损失函数都需要用到disc_fake,由discriminator前向传播,如果不保留计算图,会默认清除,
# 导致生成器的损失再用到discriminator的计算图时会报错
discriminator_optimizer.step()
# 生成器损失
disc_fake = discriminator(obs_fake)
# 必须有,adam优化器discriminator_optimizer.step()导致梯度涉及到的变量原地操作,
#不然gen_loss.backward()这句会报错
real_action_probs = victim_model.actor_local(obs_real)
perturbed_action_probs = victim_model.actor_local(obs_fake)
gen_loss = generator_loss(disc_fake, real_action_probs, perturbed_action_probs, obs_real, obs_fake)
# 更新生成器
generator_optimizer.zero_grad()
gen_loss.backward()
generator_optimizer.step()