
1、LoRA微调的矩阵初始化怎么初始化
LoRA微调使用低秩分解,将参数矩阵的变化量,分解成两个更小的矩阵B和A

其中B初始化为0,A初始化为高斯分布
B初始化为0,是为了保证训练刚开始的时候,BA是0,即初始偏移是0,也就是保证从底座大模型开始训练,确保了训练的稳定性
A高斯分布初始化,因为需要保证BA是0,同时A不能为0,又因为高斯分布的数学特性,高斯分布均值为0,方差可控,适合模型更有效的训练,所以将A设置为高斯分布初始化
如果两个都为0:导致反向传播时,AB的梯度均为0,发生梯度消失的问题
如果两个都是高斯分布:初始时就可能引发较大偏移,引入太多噪声,收敛困难
LoRA一般对attention层进行微调,也就是那4个矩阵
2、注意力机制的演变(针对推理)
最开始的Transformer,多头注意力开始,时间复杂度很高
23年谷歌的gemini大模型,使用一种MQA(Muti Query Attention)的多查询注意力机制,Key和Value原本是多个头用不一样的矩阵生成,再MQA中,多个头共用一组KV矩阵
同样23年,谷歌又提出了GQA(Grouped Query Attention)的分组查询注意力机制,把原本的n_head参数,变为了n_head和n_kv_head,可以分别指定Q矩阵和KV矩阵的个数(LLAMA2使用)
上面的都有一定的问题,可能会牺牲一定的性能来提高效率
于是DeepSeek提出了MLA(Muti Latent Attention)的多头潜在注意力机制:将原本的QKV的计算,变成了压缩和解压缩的过程,也就是将输入向量,通过一个下投影矩阵,压缩为一个低维向量,然后再通过两个上投影矩阵,反压缩成KV向量,为了降低训练过程中的内存,对Q的计算也做了同样的处理

标准的旋转位置编码(通过旋转向量对QK向量进行位置编码)和低秩压缩QKV并不兼容,deepseek引入了解耦的旋转位置编码

解耦的旋转位置编码:原本的旋转位置编码是直接通过对QK向量旋转实现编码,在解耦的位置编码中,是对输入向量降维后,引入位置编码后,再与QK向量拼接成新的向量


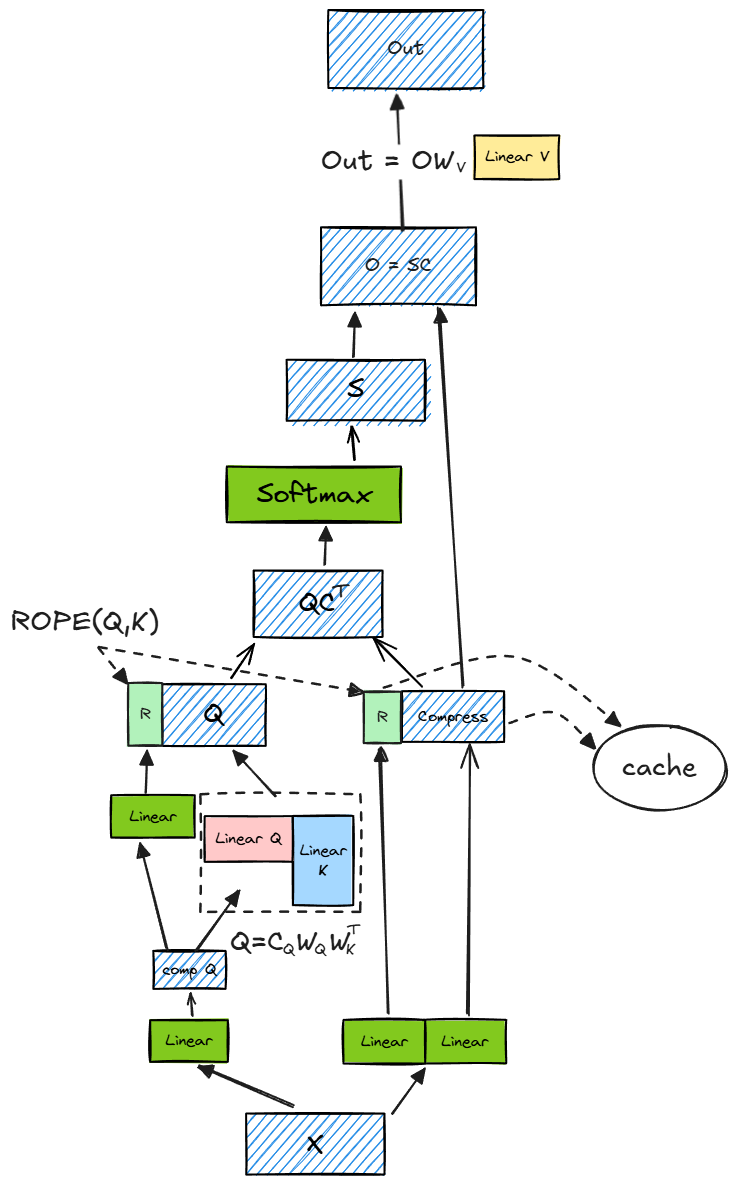
需要存储压缩后的向量与K的位置编码向量
3、Deepseek的创新
引入了多头潜在注意力机制(减少了推理时的内存,提高效率)
对混合专家模型架构(MOE)的改进

MOE中,如果专家模型选择不均衡(通过计算重要性得分来选择),会导致计算资源的浪费,传统的MOE中,是通过损失函数(尽量让每个专家的重要性得分相近)强制平衡专家模型的选择,但是可能导致性能下降
DeepSeek的话,是通过在计算重要性得分时加入动态调整的偏执,达到负载均衡的效果
引入多Token预测
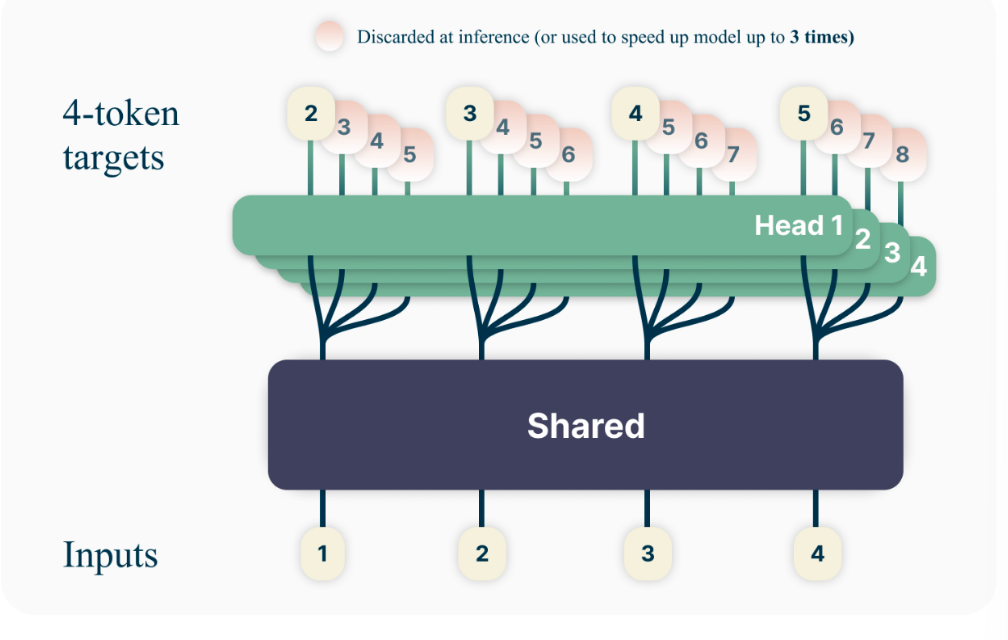
4、Bert和GPT的区别
5、LN用在哪,为什么用LN,和BN有啥区别
用在残差连接之后,因为残差连接会将上一层的输入与输出连接,可能会导致数据分布不稳定
Layer Normalization:1、让数据分布更稳定,加速训练;2、控制反向传播的梯度在一个合理范围之内,避免梯度消失或者梯度爆炸的问题
Batch Normalization:假设有10个数据,Batch Normalization对这10个数据的每个特征,分别归一化
Layer Normalization:假设有10个数据,Layer Normalization对每个数据的所有特征之间进行归一化
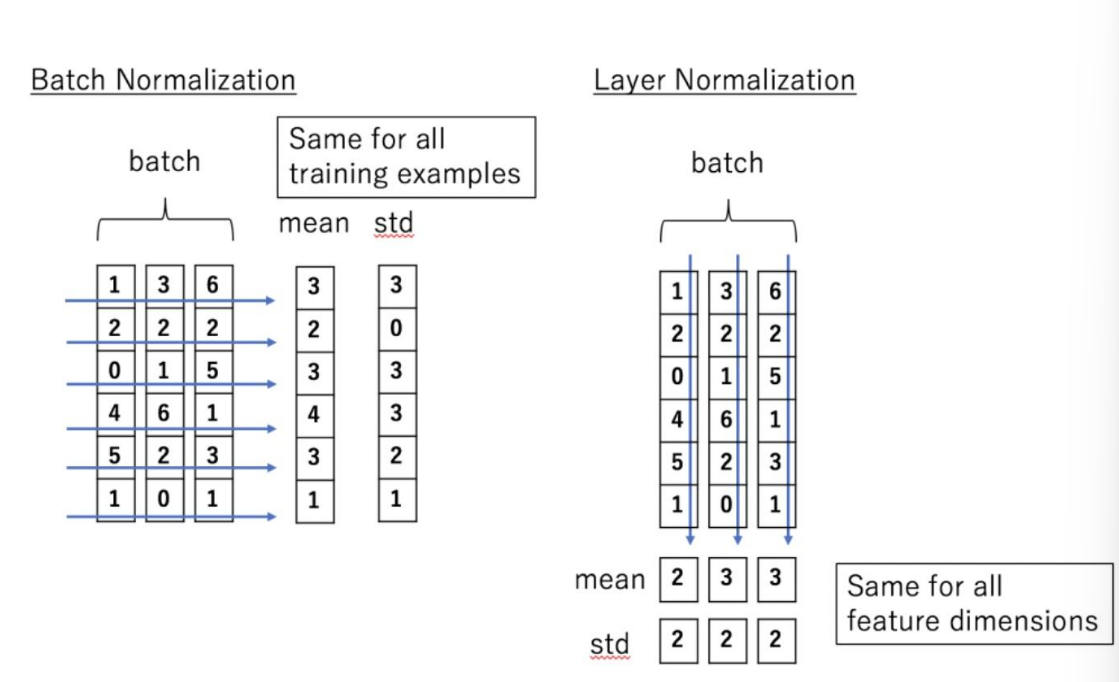
6、介绍下QLoRA
只是再LoRA的基础上,引入了模型量化的技术
存储的低秩矩阵参数仍然是16


DeepSeek R1从HuggingFace中下载是BF16
参数设置:
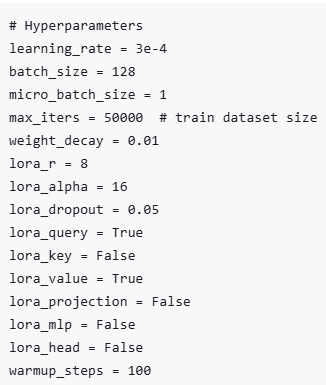
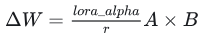
target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"]