
定义:通常用于图像、视频、语音等信号数据的分类和识别任务。其核心思想是通过卷积、池化等操作来提取特征,将输入数据映射到一个高维特征空间中,再通过全连接层对特征进行分类或回归。
核心是卷积层与池化层
卷积层:保留数据的特征(通过滑动卷积核(或滤波器)对输入图像进行处理)
池化层:池化层通常跟在卷积层之后,主要作用是对卷积层提取到的特征进行下采样,减小数据的空间尺寸,进而降低计算量和防止过拟合
卷积层

设输入矩阵大小为 w , 卷积核大小为 k , 步幅为 s , 补零层数为 p , 则卷积后产生的特征图大小计算公式为:
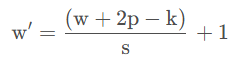
若不是方阵,特征图长宽分别用上述公式计算
池化层
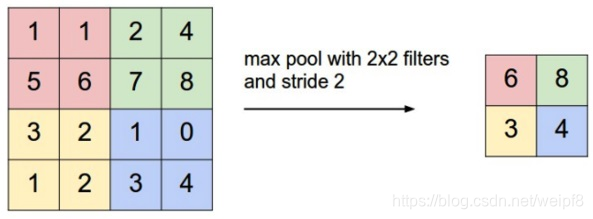
和卷积一样, 池化也有一个滑动的核, 可以称之为滑动窗口, 下图中滑动窗口的大小为 2 × 2 ,步幅为 2,每滑动到一个区域, 则取最大值作为输出,,这样的操作称为 Max Pooling,还可以采用输出均值的方式, 称为 Mean Pooling
LSTM + CNN
CNN 其实也可以应用于LSTM,LSTM 的输入是时序数据,(seq,feature)是个矩阵,可以通过 CNN 处理,下面的代码是 CNN + LSTM 的网络结构
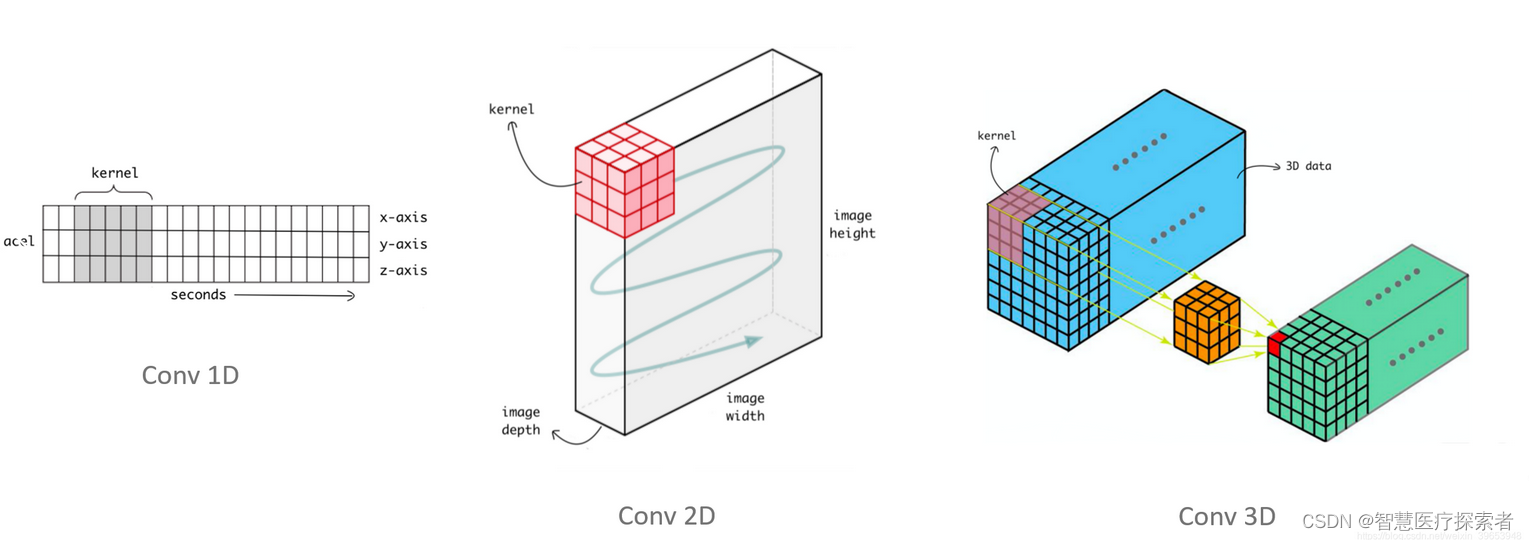
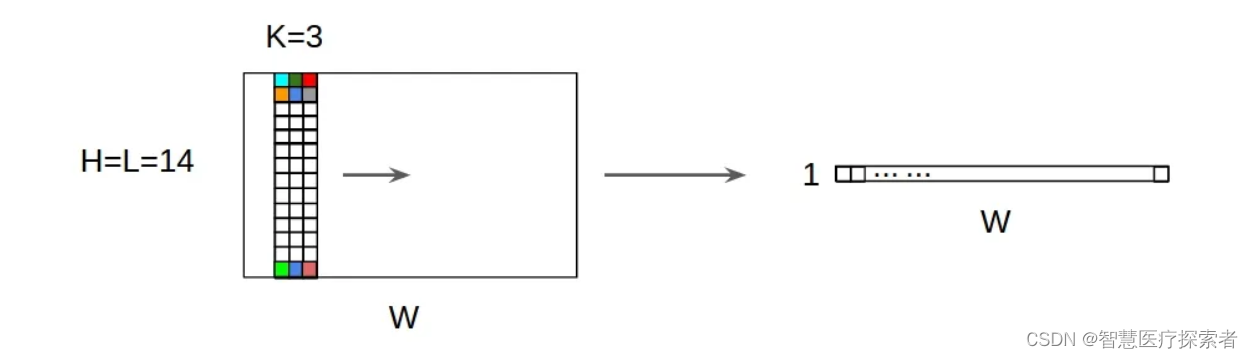
LSTM + CNN 中的 CNN 是一维卷积,图像处理则是二维卷积
Conv1d的输入是三维数据:(Batch_size, channels, width),卷积操作沿着 width 维进行,所以需要将 (batch_size, seq_len, feature_dim) 转换为 (batch_size, feature_dim, seq_len),pytorch是这样,tensorflow是从上往下扫
通俗来说:卷积核在几个维度上滑动就是几维卷积,2d先横着扫再竖着扫,1d只能竖着扫(沿着 width 维)
class CNN_LSTM(nn.Module):
def __init__(self, input_dim, output_dim, cnn_out_channels=64, cnn_kernel_size=3,
lstm_hidden_size=128, lstm_num_layers=2, dropout=0.2):
super(CNN_LSTM, self).__init__()
# 卷积层,移除池化层以保持序列长度
self.cnn = nn.Sequential(
nn.Conv1d(in_channels=input_dim, out_channels=cnn_out_channels, kernel_size=cnn_kernel_size, padding=1),
nn.ReLU(),
nn.Conv1d(in_channels=cnn_out_channels, out_channels=cnn_out_channels * 2, kernel_size=cnn_kernel_size, padding=1),
nn.ReLU()
)
# LSTM层
self.lstm = nn.LSTM(
input_size=(cnn_out_channels * 2),
hidden_size=lstm_hidden_size,
num_layers=lstm_num_layers,
batch_first=True,
dropout=dropout if lstm_num_layers > 1 else 0
)
# 全连接层
self.fc = nn.Linear(lstm_hidden_size, output_dim)
def forward(self, x):
"""
x: [batch_size, seq_length, features]
"""
# 将 x 的维度从 [batch_size, seq_len, feature_dim] 转换为 [batch_size, feature_dim, seq_len]
x = x.permute(0, 2, 1)
x = self.cnn(x) # [batch_size, cnn_out_channels*2, seq_length]
# 将CNN的输出转换回LSTM需要的形状 [batch_size, seq_length, cnn_out_channels*2]
x = x.permute(0, 2, 1)
# LSTM
lstm_out, _ = self.lstm(x) # lstm_out: [batch_size, seq_length, lstm_hidden_size]
# 全连接层应用于所有时间步
out = self.fc(lstm_out) # [batch_size, seq_length, output_dim]
return outConv1d详解
参数详解
torch.nn.Conv1d(in_channels, "输入图像中的通道数"
out_channels, "卷积产生的通道数"
kernel_size, "卷积核的大小"
stride, "卷积的步幅。默认值:1"
padding, "添加到输入两侧的填充。默认值:0"
dilation, "内核元素之间的间距。默认值:1"
groups, "从输入通道到输出通道的阻塞连接数。默认值:1"
bias, "If True,向输出添加可学习的偏差。默认:True"
padding_mode "'zeros', 'reflect', 'replicate' 或 'circular'. 默认:'zeros'"
)在 LSTM-CNN 中,in_channels 则是特征维度,padding 为1,stride为1,确保 CNN 的输出最后一维还是 seq_leg,即让特征图大小计算公式中的 w = w’
