
策略梯度方法
要得到更好的策略,即让该策略下,状态价值均值很大
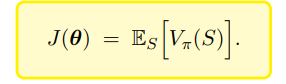
可以用梯度上升去更新策略网络,对状态价值均值求导可转换为对策略网络求导
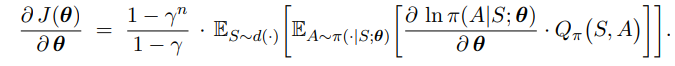
无法直接求出这个期望,因为不知道状态 S 概率密度函数,可以使用采样的方式去近似,g(s, a; θ) 是策略梯度 ∇θJ(θ) 的无偏估计

处理Q(S,A)有两种办法
REINFORCE,蒙特卡洛,直接用回报代替Q(同策略)
Actor-Critic中,用Critic估计Q(使用SARSA,也是同策略)

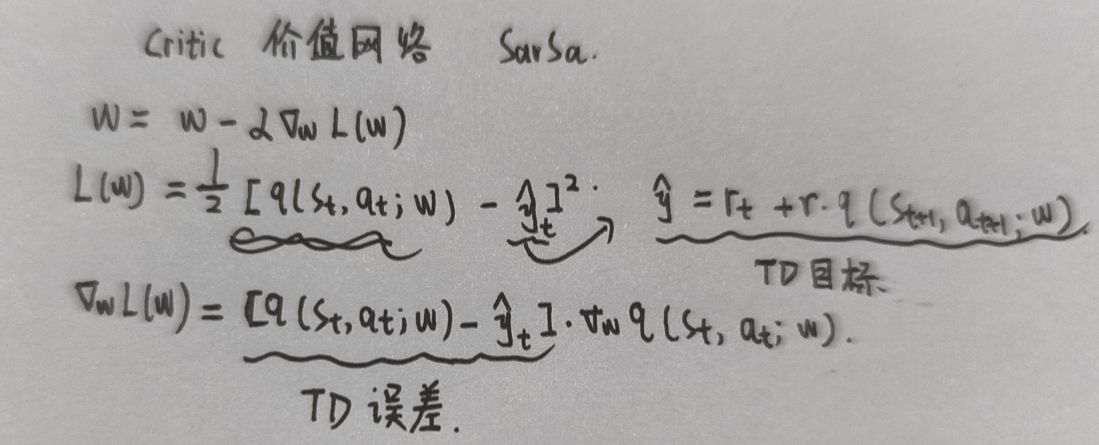
Critic存在自举问题,引入目标网络解决
引入基线提高策略梯度方法的表现
基线
引入一个b

带基线的REINFORCE
引入一个状态价值网络代替 b 作为基线
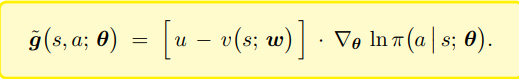
带基线的Actor-Critic(A2C)
同样引入一个状态价值网络代替 b 作为基线,经过公式推导,只需要一个状态价值网络即可,不需要动作价值网络:
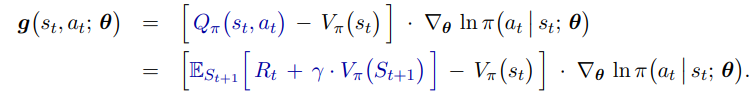
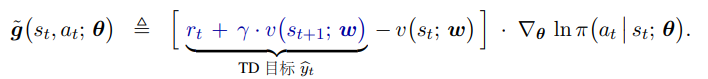
同样,仍存在自举问题,可以引入目标网络
