
QAC、A2C、A3C 均是 on policy 的强化学习算法
QAC、A2C、A3C 均是基于策略的强化学习算法,以 actor-critic 为基础架构,其中 actor 为策略网络,critic 为评价 actor 中当下策略的网络
actor 的目的是从 critic 网络得到高评价,critic 的目的是使当前 actor 网络策略评价的更准,actor 网络的梯度如下:
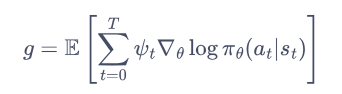
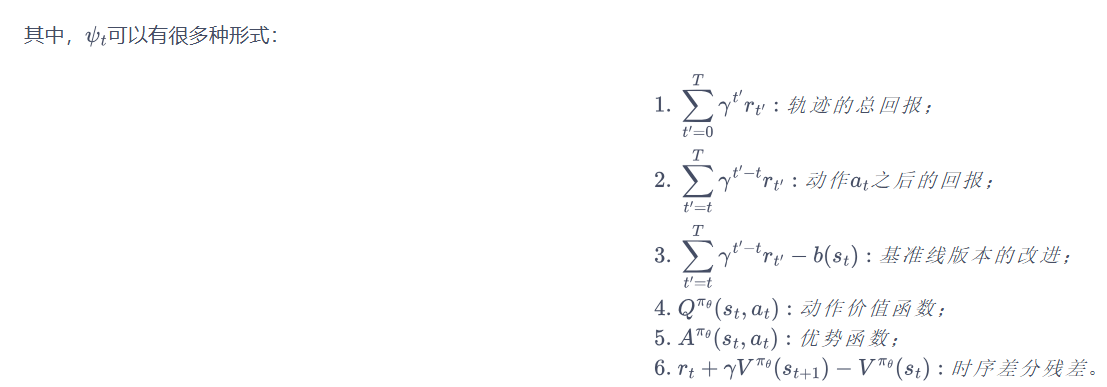
QAC
在 QAC 算法中,actor 网络梯度使用 4 的形式
在 QAC 算法中,critic 网络估计的是动作价值函数,使用 sarsa 算法更新(本质还是 TD 误差),更新过程如下:

A2C
在 A2C 算法中,actor 网络梯度使用 6 的形式(从 5 推出 6)
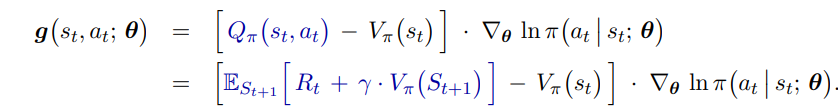
在 A2C 算法中,critic 网络估计的是状态价值函数,使用 TD 误差来更新,更新过程如下:

注
1、A2C 舍弃掉了形式 4 ,好处是啥?
答:A2C 使用形式 5 实际上是引入了基线,保持期望不变的同时,可以降低方差
2、为什么无论是动作价值函数,还是状态价值函数,都可以用类似的 TD 误差形式更新
答:因为状态价值函数与动作价值函数有着相似形式的贝尔曼方程,都是用采样去估计从而去掉期望,所以有着类似的 TD 误差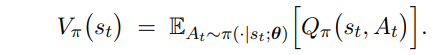



A3C
A3C 只是在 A2C 的基础上引入了异步训练、多步回报
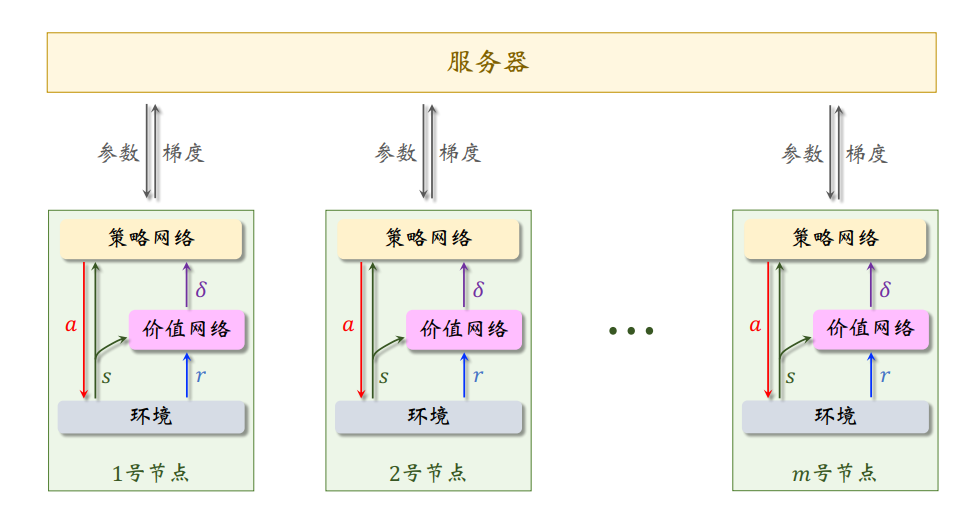
在异步算法中,一个 worker 节点无需等待其余节点完成计算或 通信。当一个 worker 节点完成计算,它立刻跟 server 通信,然后开始下一轮的计算
在A3C中,有一个全局网络(global network)和多个工作智能体(worker),每个智能体都有自己的网络参数集,与它自己的环境副本交互
worker 端:

服务器端:

